
The Evolution of Things Solver
Things Solver started as a startup in late 2015 with some of the pioneering projects in Eastern Europe. Today Things Solver is a team of 50+ people running its operations under the ASEE Group.

Hands on Experience
We have built our experience across many industries simply by running more than 100 successful projects. Hands-on experience at its best.

Global Trust in Data Transformation
Some of the most eminent companies all over the world trust us with their data transformation. From Brazil to the USA and ex Yugoslavia, you name it we have done it.
How do we see no BS approach?
What are the things our customers feel working with us

Modular
Designed with flexibility in mind. Take what you need and pay what you need.
Simple
Simple to use and focused on UI/UX to deliver the best experience to our customers.
AI-Driven
Using AI models where is needed but only “when” is needed. No hype, just pragmatic.
What we deliver to the world
Don’t lose your customer’s attention with irrelevant experiences. Provide super customer experience by serving up personalized services, products, content, and recommendations for each individual. Make that and watch engagement rates skyrocket.
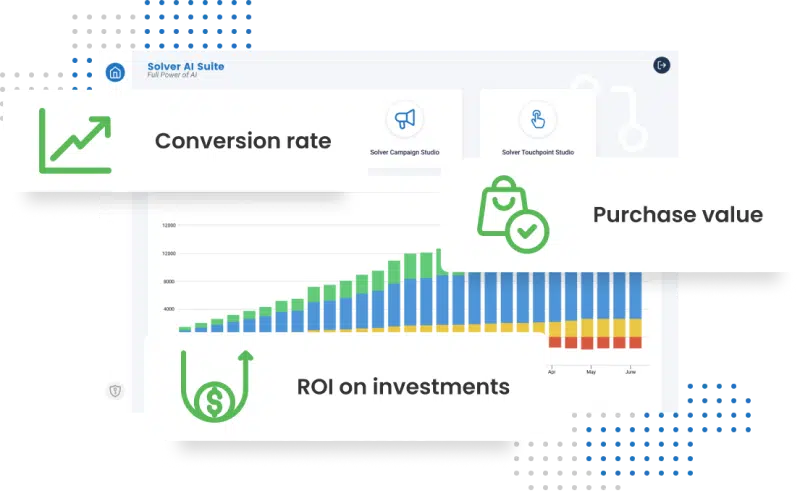
35%
average conversion rate increase
3x
better ROI on interactions
36%
purchase value increase

SOLUTIONS FOR CONCRETE RESULTS
Solver AI Suite represents an end-to-end AI solution for enterprises that would like to properly segment customers and personalize audiences or forecast sales without employing a team of people to implement or understand the data.
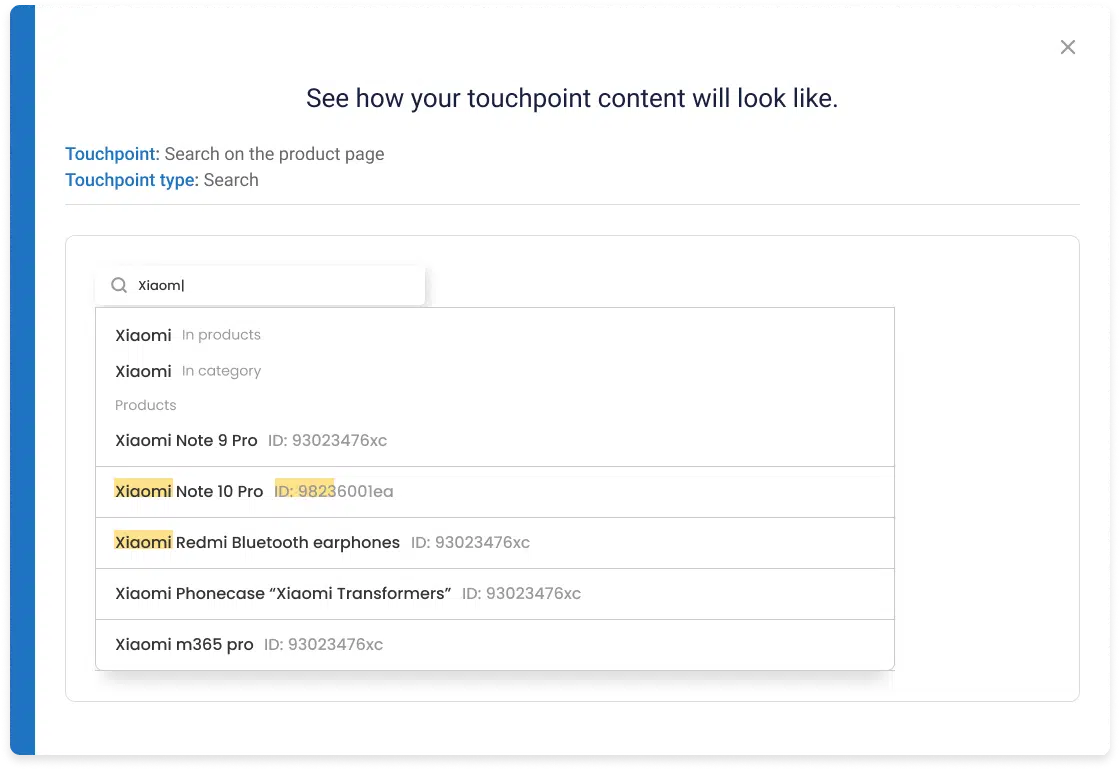
Search process that will become your the most effective salesman
Eliminating typos and misspellings within the customer searching process will make your website the most intelligent salesman ever.
Our AI models help your visitors easily navigate your offering by offering the right products in the search results.
This is possible because our system understands customer search intent and compares it with their behavior to serve the ideal products or services to your existing or new customers.
Intelligent customer insights that help you personalize your offer
By making a customer journey and purchasing experience fully personalized for your customers will make them feel more comfortable buying from you.
The way how we help our customers implement a personalized customer experience and intelligent product recommendations is by utilizing AI-powered segmentation and recommendation engine that help you offer only relevant and personal shopping experiences.
This helps you deeply engage with your customers while running a revenue predictive business where you can be sure you will boost your conversion rate by no less than 30%.
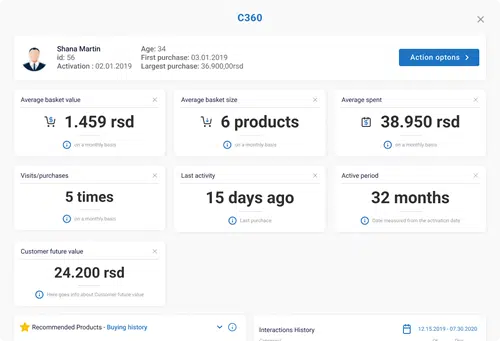
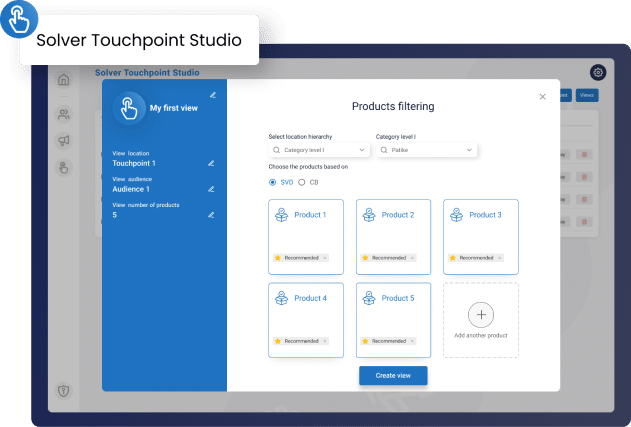
Easily sell more at your website by managing touchpoints
Automatically upsell across all touchpoints.
Use collected data to better understand what your customer's real needs are so you could offer the proper solution to their problem.
With AI-based customer segmentation and understanding of individual customer purchasing intent, you will know exactly where and when to place a product or service at your website or an eCommerce so you can implement automatic offer recommendations that really matter to your website visitors.
This will help your eCommerce decrease a churn rate by at least 20% almost instantly while increasing your conversion rate.
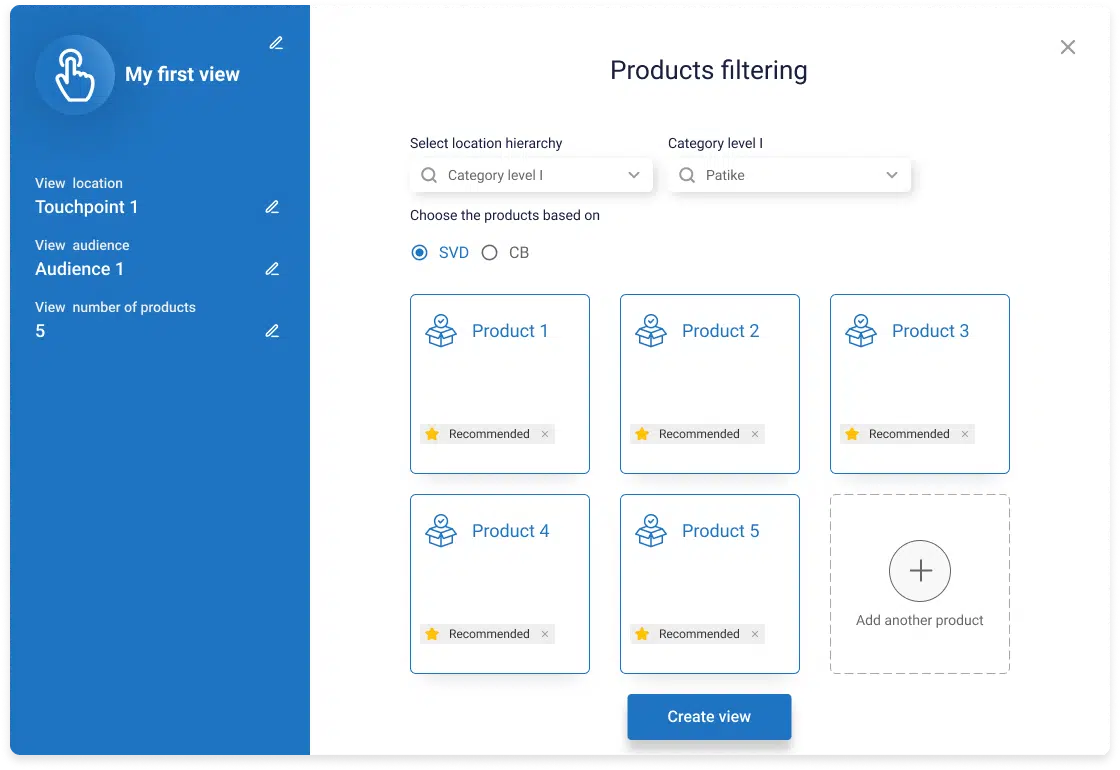
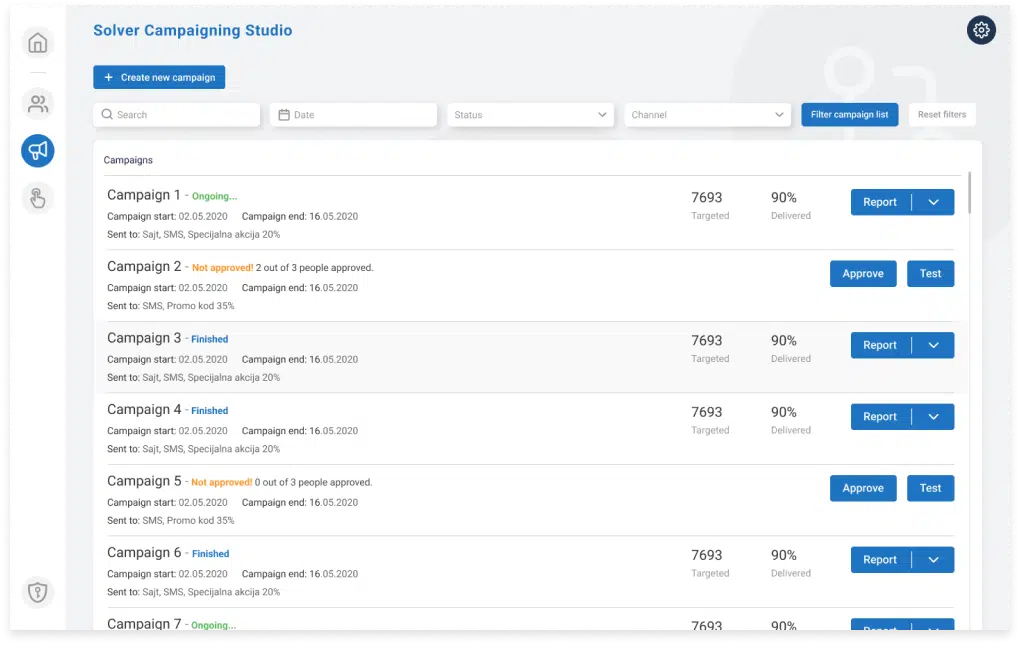
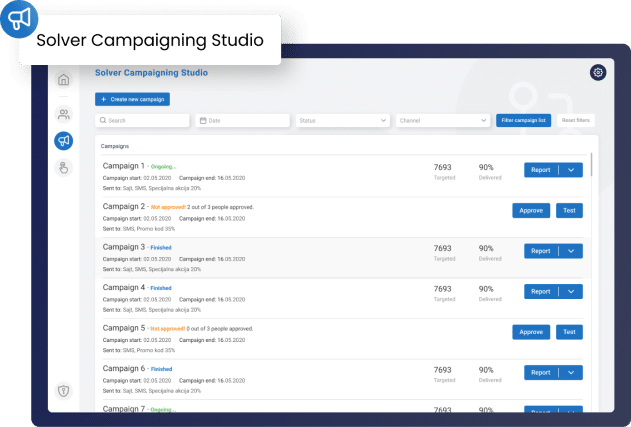
Run high converting campaigns based on customer insights
How about a machine choosing for you the most converting audience and a communication channel?
This is exactly what our solution does for you, automatically selecting the most appropriate channel per specific audience so you could get the highest converting campaigns.
How this is possible?
Easily as our solution properly segment and personalize your customer data and group them so that Campaigning Tool will easily understand on which channel to send the message that will result in a conversion.
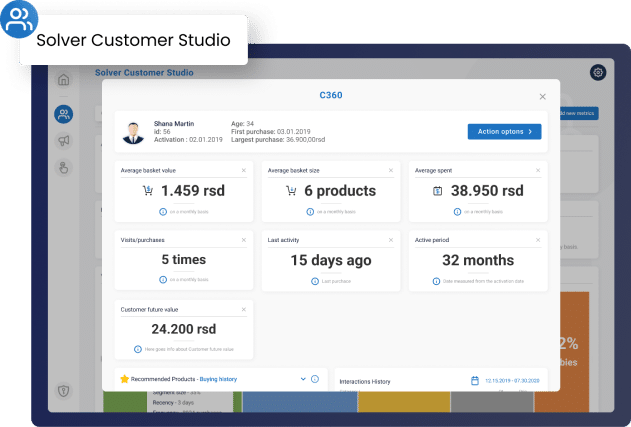
Meet the products
Solver AI Suite, big data, and machine learning platform for smart business predictions.
Start the process
Discover what’s possible with Solver AI Suite. Drop us a message and our consultants will reach out ASAP to show you how to start working smarter and more efficiently with Solver AI Suite.