Kako povećati online prodaju u ovoj prazničnoj sezoni uz personalizovano kupovno iskustvo
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
11. 01. 2018.

Problem detekcije anomalija je veoma izazovan problem sa kojim se firme često suočavaju u analizi podataka. Bilo da se radi o grupisanju, klasifikaciji ili nekom drugom problemu mašinskog učenja, od velike je važnosti identifikovati anomalije i tretirati ih na neki način kako bi se postigle optimalne performanse modela. Pored toga, anomalije često mogu uticati na rezultate analize, što može biti uzrok donošenja pogrešnih zaključaka, utičući na donošenje važnih poslovnih odluka. Dakle, u svakoj analizi podataka potrebno je precizno definisati anomalno ponašanje u određenom domenu, primeniti odgovarajući model detekcije anomalija, izdvojiti anomalije iz ostatka podataka i zatim nastaviti sa analizom, primenom modela i izvođenjem zaključaka.
Iako se anomalije često smatraju nekom vrstom nepravilnosti koje unose šum u podatke, one u sebi mogu sadržati više informacija nego što se ranije verovalo. Pojam „anomalija“ se često (i rekao bih pogrešno) koristi kao sinonim za pojam „odstupanje“. To nije velika greška, pošto ih ceo svet koristi kao sinonime. Volim da ih razlikujem opisujući njihovu razliku na sledeći način: „Odstupanje“ je instanca koja se značajno razlikuje od ostalih instanci na osnovu svojih vrednosti, ili se dešava nasumično i retko u poređenju sa ostalim instancama, pa se stoga može smatrati irelevantnom za analizu, dok je „ anomalija” ponašanje koje je drugačije od očekivanog u odnosu na neko prethodno zabeleženo ponašanje i zahteva dublje zaranjanje i analizu uzroka. Na primer, u nekoj telekomunikacionoj mreži možemo da imamo ćeliju koja je preopterećena, a u ovom slučaju – smatra se da je odstupajuća među ostalim ćelijama u mreži. Ali ako se desi da u istoj mreži u određenom vremenskom periodu nekoliko različitih ćelija ima problem preopterećenja, one kao grupa mogu predstavljati anomaliju do koje je došlo, na primer, usled kvara nekog linka, ili zagušenja na linku koji ih povezuje.
Proces detekcije anomalija treba da uključuje sledeće korake, kako bi se sproveo na pravi način:
Anomalija predstavlja tip ponašanja u podacima koji se razlikuje od nekog očekivanog ponašanja. Dok se odstupanje može tumačiti kao instanca koja odstupa od ostalih instanci, bez ikakvog značenja, čije se ponašanje može lako objasniti i na taj način ignorisati i ukloniti, anomalije predstavljaju grupisane ili korelirane ekstreme, odstupanja koja imaju dublji uzrok različit od običnih ljudskih grešaka ili pogrešno čitanje, nepravilnosti koje nije tako lako otkriti i objasniti, jer su obično skrivene među normalnim slučajevima.
Anomalije se mogu grupisati u tri sledeće klase:
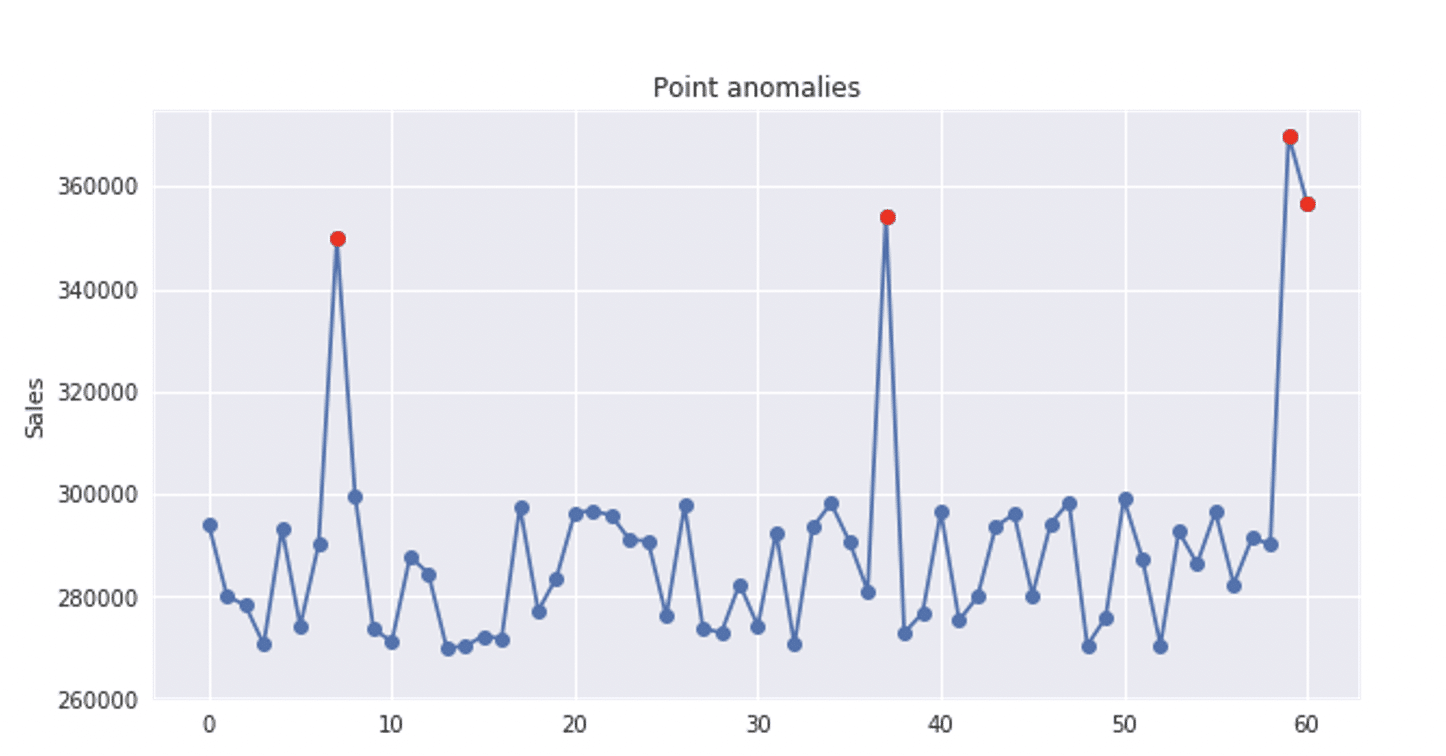
Anomalija tačaka, kao što pojam kaže, je instanca koja se može smatrati anomalnom među ostalim instancama u skupu podataka. Anomalije tačaka često predstavljaju neki ekstrem, nepravilnost ili odstupanje koje se dešava nasumično i nemaju posebno značenje. Volim da to nazivam odstupanjem. Na grafikonu vremenskih serija u nastavku, crvene tačke predstavljaju izolovane anomalije tačaka.
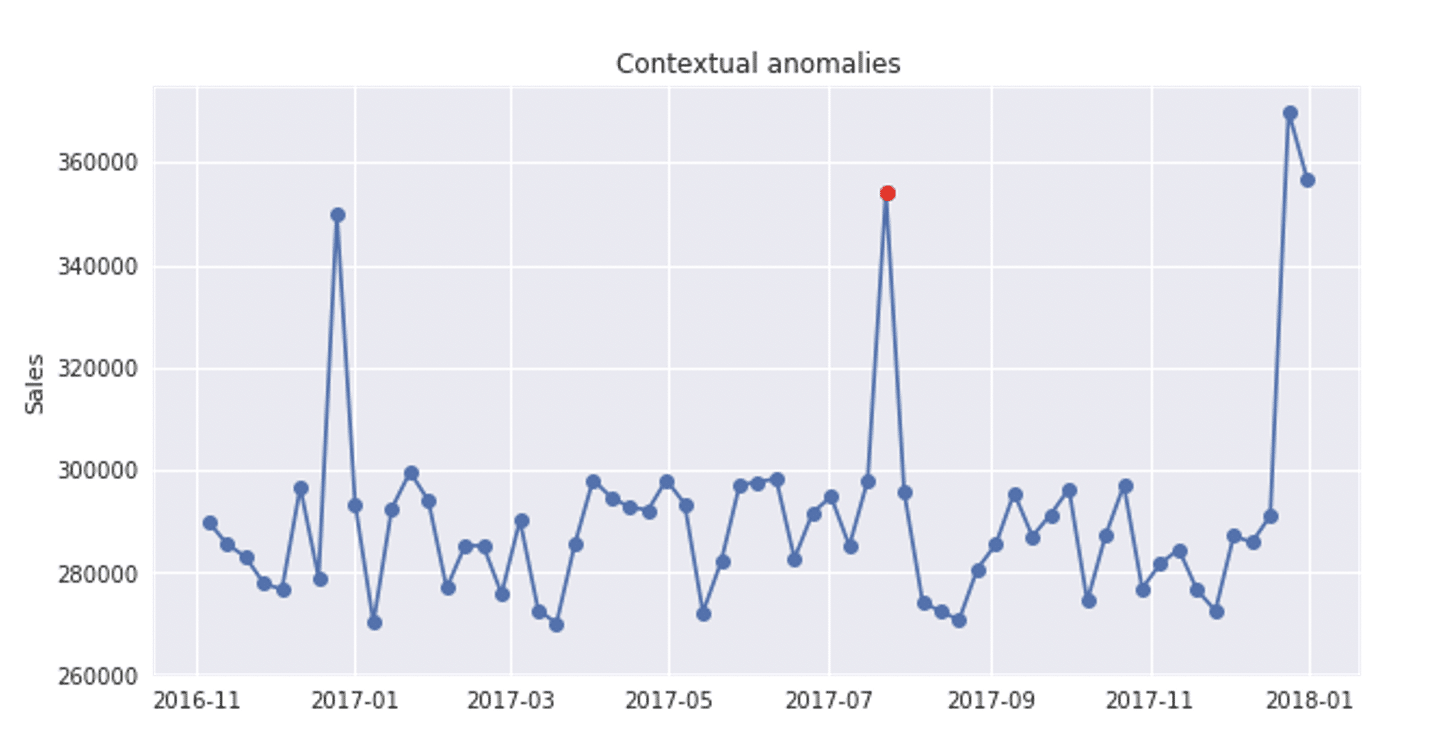
Kontekstualna anomalija je primer koji bi se mogao smatrati anomalnim u nekom specifičnom kontekstu. To znači da nam posmatranje iste tačke kroz različite kontekste neće uvek dati indikaciju anomalnog ponašanja. Kontekstualna anomalija je određena kombinovanjem kontekstualnih i bihevioralnih karakteristika. Za kontekstualne karakteristike najčešće se koriste vreme i prostor, dok bihevioralne karakteristike zavise od domena koji se analizira – utrošenog novca, prosečne temperature ili neke druge kvantitativne mere koja se koristi kao obeležje.
Ako dodamo neku kontekstualnu karakteristiku, kao što je vremenska dimenzija, ista vremenska serija će izgledati kako sledi. Slične vrednosti su različito označene za različite vremenske periode. Ako dolenavedena vremenska serija prikazuje prodaju za svaki mesec, sezonski vrhovi u periodu praznika (decembar) predstavljaju rast prodaje zbog većeg broja kupovina, dok vrhunac u julu 2017. predstavlja neočekivani, anomalan rast, koji zahteva dublju analizu kako bi se objasnio – uzrok može biti neka prodajna akcija, muzički festival ili sportski događaj. Postoje baze za otkrivanje anomalija koje imaju mogućnost da prime vremenske periode za koje se očekuje da imaju ekstremne vrednosti za neku osobinu koja se analizira.
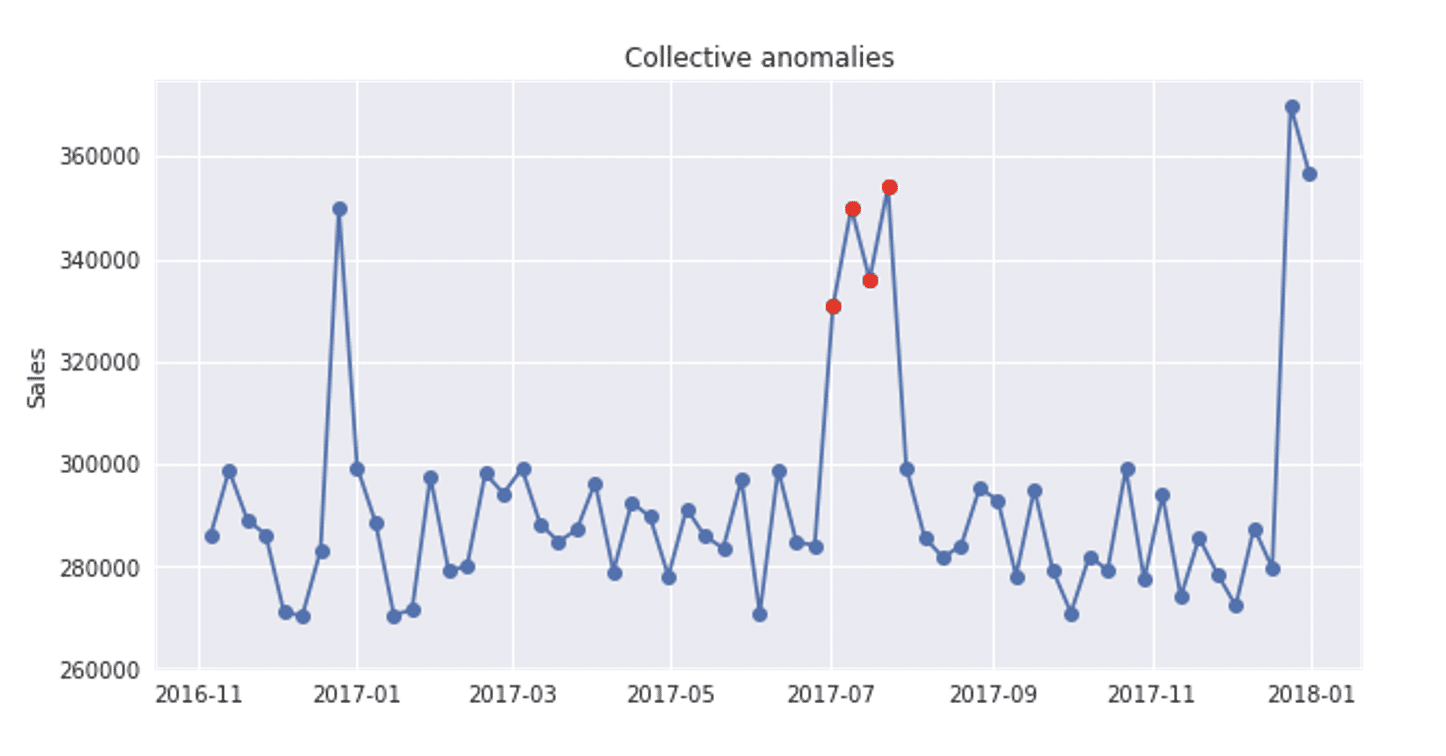
Kolektivna anomalija se često predstavlja kao grupa koreliranih, međusobno povezanih ili sekvencijalnih instanci. Iako svaka posebna instanca ove grupe ne mora sama po sebi biti anomalna, njihova kolektivna pojava je anomalna.
Vremenska serija u nastavku je prilično slična prethodnoj, osim što je rast zabeležen za ceo jul 2017. Pošto je reč o jednokratnom događaju, nema sumnje da je reč o anomalnom ponašanju.
Veoma je važno naglasiti da kontekstualne i kolektivne anomalije ne zahtevaju posebno rukovanje, već dublju analizu i identifikaciju uzroka. Ponekad je veoma važno dati dragoceno objašnjenje osnovnog uzroka kako bi se ove vrste anomalija rešile i izgladile na odgovarajući način.
Svaka tehnika detekcije anomalija pripada jednom od sledećih osnovnih pristupa:
Izbor pravog skupa tehnika zavisi od dostupnih podataka. Sa označenim podacima, odluka je prilično jednostavna. Može se mnogo uraditi kada se daju informacije o normalnom i anomalnom ponašanju. Sa delimično označenim ili neoznačenim podacima, ovaj zadatak je složeniji i predstavlja svojevrsnu umetnost. Detaljan opis najpoznatijih tehnika detekcije anomalija se može naći ovde, zajedno sa pretpostavkama koje je potrebno ispuniti za svaku od njih kako bi bile iskorišćene, kao i prednostima i nedostacima, kao i potrebnom složenošću računara.
U svom sledećem postu, govoriću o algoritmu Isolation Forest i kako se on može koristiti za detekciju anomalija u podacima.

Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Detaljniji pogled na ono što AI analitika zaista znači Obučili ste svog AI agenta. Radi. Priča. Reaguje. Ali, da li…
Read more
Agentna veštačka inteligencija Zamislite da imate tim vrhunskih kuvara, ali vam je frižider pun pokvarjenih sastojaka. Bez obzira na to…
Read more