Kako povećati online prodaju u ovoj prazničnoj sezoni uz personalizovano kupovno iskustvo
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
31. 08. 2017.

Zdravo svima. Iako sam planirao da moj sledeći post bude o detekciji anomalija i njihovom tretmanu, suočio sam se sa drugom vrstom problema koji je brzo prerastao u ogroman problem koji utiče na modeliranje i tačnost rezultata i nisam mogao da odolim da što pre podelim svoje iskustvo. U ovom postu ću govoriti o problemu rukovanja nedostajućim podacima.
Nedostatak podataka predstavlja svakodnevni problem za analitičara. Navikli smo se na njega i najčešće ga samo tretiramo nekim standardnim tehnikama i nastavljamo sa analizom. To je ono što sam radio dok nisam shvatio da to ne daje zadovoljavajuće rezultate.
Svi smo naučeni da je najlakši način za rukovanje nedostajućim vrednostima da ih ispustimo, naravno, ako ih nema previše. Ako postoji značajan broj nedostajućih vrednosti, neke druge opcije uključuju popunjavanje određenim vrednostima. Najzahtevniji deo ovde je odlučivanje kako treba popuniti te nedostajuće vrednosti podacima.
Pre donošenja ove odluke, važno je znati da postoje tri vrste nedostajanja podataka i nije šteta ako još niste čuli za to – moram priznati da sam to nedavno saznao.
Mogući tipovi podataka koji nedostaju su:
Najvažnija stvar koju treba primetiti je da se treća vrsta nedostajanja ne može rešiti. Dobre vesti su – druge dve mogu. Dakle, ako je tip nedostatka MCAR ili MAR, ali podaci nisu modelirani, ceo proces bi rezultirao niskom efikasnošću, a u drugom slučaju – pristrasnošću. Zaključak je – trebalo bi to nekako modelirati i doći ćemo do toga. Ali prvo, hajde da navedemo tehnike tretmana.
| ID | x | y | z | w |
| 1 | 2,50 | 0,18 | 10,50 | – |
| 2 | – | – | – | – |
| ID | x | y | z | w |
| 1 | 2,50 | 0,18 | 10,50 | 55 |
| 2 | 2,70 | 0,23 | 11,75 | – |
| … | … | … | … | … |
| 3 | 1,50 | 0,12 | 12,80 | 19 |
MICE algoritam se koristi kada se suočava sa problemom MAR nedostajućih podataka – podaci koji nedostaju nasumično, ali zavise od vidljivih varijabli. Obično se sastoji od ovih koraka:
Laka logika, i što je još važnije, došao sam do tako lepe implementacije koja dodatno olakšava korišćenje ovog algoritma. Biblioteka se naziva fancyimpute, a samu biblioteku i dokumente možete naći ovde. Kao i obično, neću vas mnogo gnjaviti sa kodom, možete ga pronaći na linku, i to je zaista svega dva reda koda.
Testirao sam ovu biblioteku na dva načina. Prvo sam je pokrenuo za objekat čije su karakteristike bile u potpunosti ispunjene. Nasumično sam postavio neke vrednosti na nulu, a zatim pokrenuo model. Nakon ovoga, izračunao sam RMSE između imputiranih i stvarnih vrednosti, i RMSE je bio prilično zadovoljavajući.
Moj skup podataka za testiranje je izgledao ovako.
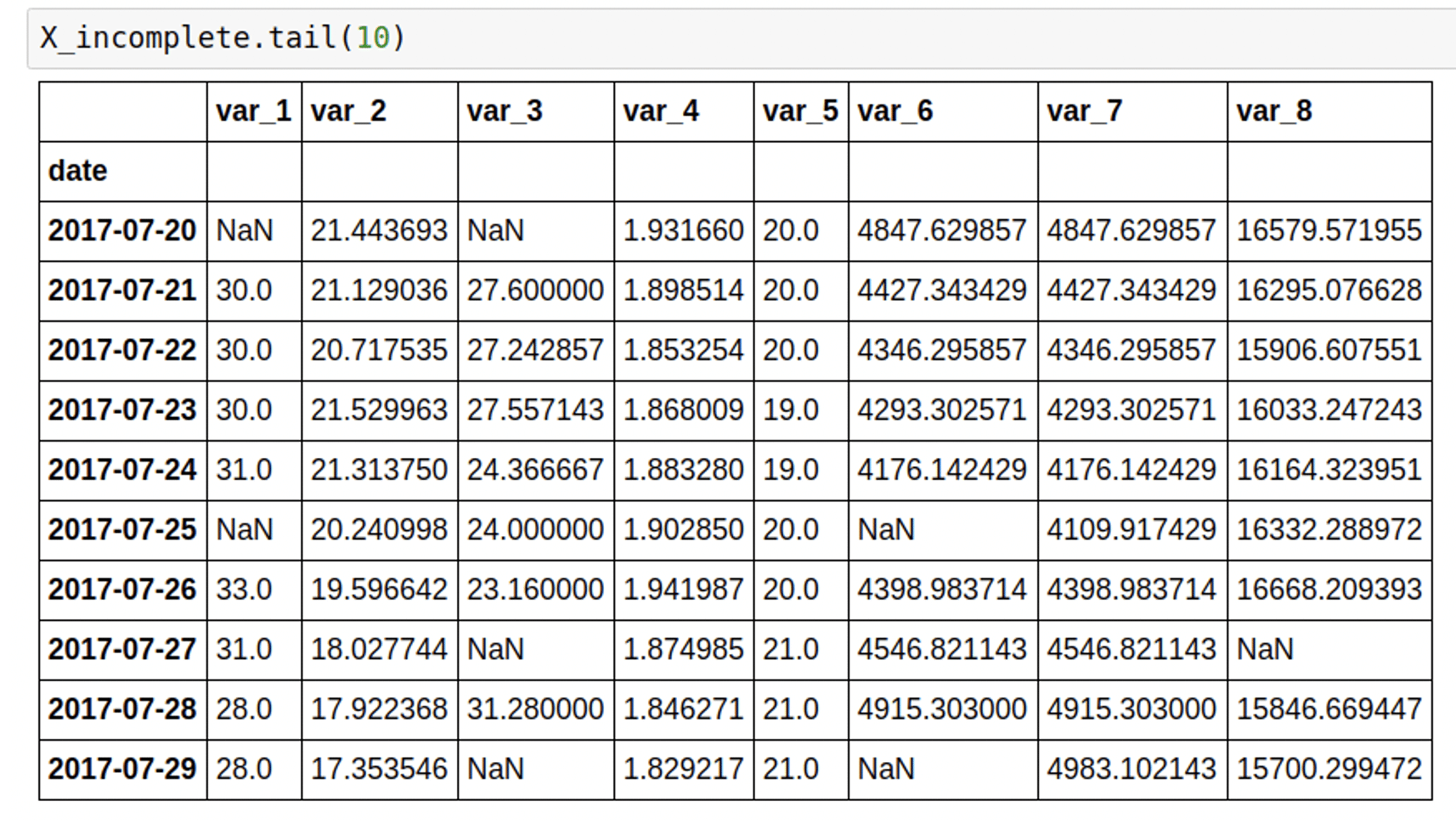
Evo koda
# import the library from fancyimpute import MICE # convert dataframe to matrix, to make it workable with X_incomplete_matrix = X_incomplete.as_matrix() # call the function to impute the values X_filled_mice = MICE(min_value=0).complete(X_incomplete_matrix) # make a dataframe out of results X_complete_with_mice = pd.DataFrame(X_filled_mice, columns = X_complete.columns)
Bilo je lako uporediti rezultate sa X_complete, koji je sadržao stvarne vrednosti. U nastavku možete videti valjanost uklapanja.
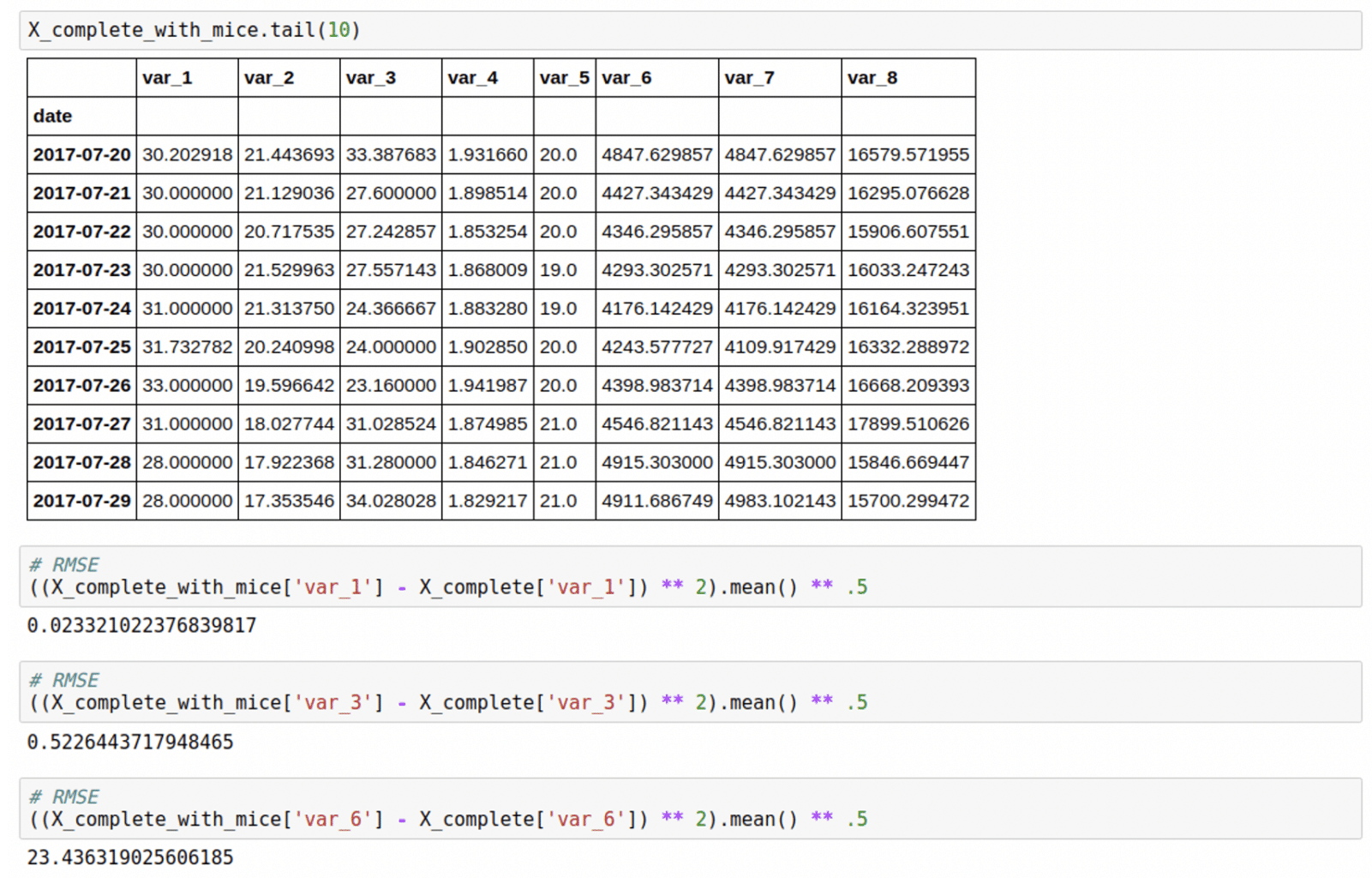
Naravno, RMSE zavisi od broja nedostajućih vrednosti, što je više nedostajućih vrednosti – veća je greška. Zato smo izveli jednu dodatnu funkciju za svaku instancu koja bi nam pomogla da radimo sa skupom podataka, tumačimo rezultate i donosimo odluke, što se naziva „pouzdanost“. Pouzdanost jednaka 100 znači da instanca ima vrednosti za sve karakteristike, i ona se smanjuje kako se broj vrednosti koje nedostaju povećava.
Drugi način validacije uključivao je konsultacije sa stručnjakom za domen i njegovu reč odobrenja. Zaključili smo da su nedostajuće vrednosti prilično precizno imputirane, tako da možemo normalno da nastavimo sa analizom.
U budućnosti ću više istraživati druge metode rukovanja nedostajućim vrednostima i ovde ću podeliti svoja iskustva. Bio bih srećan da čujem da je neko probao i ovaj, ili bilo koji drugi algoritam implementiran u gore pomenutoj biblioteci. Naravno, ako imate bilo kakvih pitanja, molim vas, ne ustručavajte se da komentarišete ispod, potrudiću se da odgovorim jasno i što je pre moguće.

Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Detaljniji pogled na ono što AI analitika zaista znači Obučili ste svog AI agenta. Radi. Priča. Reaguje. Ali, da li…
Read more
Agentna veštačka inteligencija Zamislite da imate tim vrhunskih kuvara, ali vam je frižider pun pokvarjenih sastojaka. Bez obzira na to…
Read more