How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
01. 03. 2021.

According to Gartner, only 15% to 20% of data science projects get completed. Of those projects that did complete, CEOs say that only about 8% of them generate value. Despite these facts, data science is still considered as an opportunity for business growth. These facts are something that always lingers in the back of everyone’s involved in the data science project mind. They motivate data scientists but even more delivery managers to improve their work and constantly re examine project delivery and management approaches. What’s behind the high failure rate and how can we change this?
Let’s examine the project flow we like to stick to in Things Solver when working on products and solutions for clients coming from different industries and expecting different business benefits from our deliverables.
At the very beginning of the client-vendor partnership, as we are approached as someone that can make company X become data driven and therefore make smart and automated decisions regarding the maintenance or advancement in never ending market competition game, we firstly try to get accurate ideas about clients strengths, weaknesses, opportunities and threats. Those four dimensions should be examined both through the business and data science lenses. From the half decade experience in vendoring clients with data driven problem solutions, we came across two patterns of early stage partnerships. Company X (client) wants us to provide a data science product/solution because they’ve read/heard about the positive impact that data science can bring to their business or because data science is expected to be the company’s last hope to find additional revenue streams and that way save the company’s future. Here comes two usual scenarios. First, company X has absolutely no idea how it is going to become data driven, what areas of business should be affected by the shift and how it can utilise our deliverables in order to maximise their value and business impact. They just know they want to become a data driven company and be perceived as such. Second, company X has a pretty good idea what it wants from data scientists. They have noticed that their business operations need enhancements in a certain area, they can provide their domain expertise for tackling the problem and data scientists are expected to materialise the solution at the end. While the second scenario sounds better, it doesn’t mean that starting from the first scenario will make the project less successful or fail at the end.
So, when the client has enthusiasm to start a data science journey but vague ideas how, we like to organise a couple of workshops with business representatives across the company’s departments and talk and listen, A LOT. That way we are able to help the client to come up with contours of their future data strategy. Initially, we like to talk about:
That way we can identify potential use cases we will work on. Despite the fact that we’ve usually already worked in the same industry and similar use cases this is always a perfect opportunity for us, as a vendor to enhance our business understanding and to keep up with the industry trends.
When we finish with definition of potential use cases we like to discuss the data itself. Search for answers to questions like following can help us:
After we’ve got business understanding and general data understanding, we like to conduct evaluation of potential use cases on a couple of levels. We’d like from our client to get business impact and priority evaluation of use cases while we work on technical complexity and effort needed evaluation. These can help us to separate use cases to four categories:
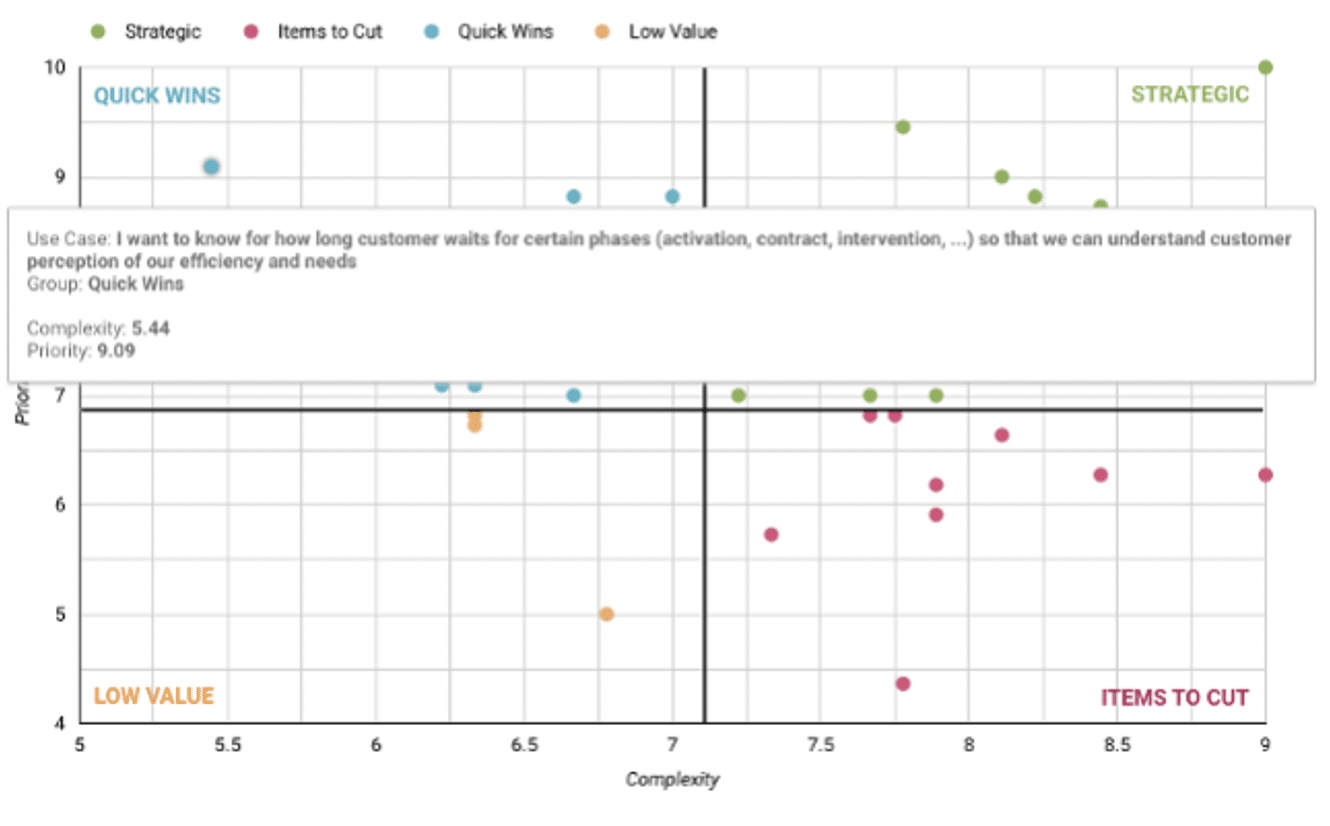
By now, we as a vendor and company X as a client have the following: initial business understanding, clear definition of business problems, list of potential use cases and initial data understanding. Next step is to define:
This is the moment when we work on a scoping phase of the project. Scoping phase regarding the chosen use case should start with product/solution requirements coming from the business side. This can sound as following “we want to know what are the main churn drivers and how to prevent customer churn”. Scoping phase also includes initial solution ideation and this usually mostly relies on data scientists. This initial solution ideation means creation of different rough sketches for possible solutions. After this, data engineers (and/or data scientists) approach the phase of data preparation and accessibility. Scoping phase should end with finalized scope and approved KPIs (business and technical) that will be monitored onwards.
Research phase comes right after the scoping phase. This phase deals with data exploration, literature and solution review, technical validity check, research review and scope and KPIs validation. During the research it is important not to lose focus and get paralyzed with possible approaches for finding a solution.
In the development phase, the team works on the experiments framework setup, model development and test and KPIs check. It is important to say that both research and development phases are highly iterative processes and usually take a couple of weeks per iteration.
Finally, in the deployment phase focus is on the productization of the solution and monitoring of the setup. That way we have finished the cycle of delivery and what is left is maintenance of delivered solution and long lasting partnership.
The process of delivery that I have just described is something we try to follow whenever is possible and reasonable but, of course, that doesn’t mean 100% of projects have this exact delivery flow. Having worked on a numerous data science projects so far I would like to point out to some findings or better said lessons learned:
Cover photo taken from: https://unsplash.com/s/photos/delivery

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more