How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
29. 05. 2023.

In today’s data-driven business landscape, effective Master Data Management is key.
The amount of data enterprises generate and collect is growing at unprecedented speed.
Everyone agrees that data can deliver the edge a business needs to be successful.
However, the requirement to be data-driven has pushed many businesses to frantically acquire as much data as possible without paying much attention to the usability of the acquired data.
So, we now have businesses sitting on enormous amounts of disparate and unreliable data scattered across many different platforms, teams, and services – but little value or insights.
The key struggle most businesses face is cleaning and consolidating all this data into a coherent and powerful business asset.
In today’s blog post, we will:
Let’s start!
Master Data Management is the process of creating unified, accurate, and consistent data. It is a holistic approach that considers all available data and works towards building a single master record for each entity in the data.
MDM typically includes essential business information such as:
MDM is crucial for business success – it provides a solid foundation for data-driven decision-making, operational efficiency, and compliance.
Two key components of the Master Data Management process are deduplication and entity resolution. Let’s explain the two concepts briefly.
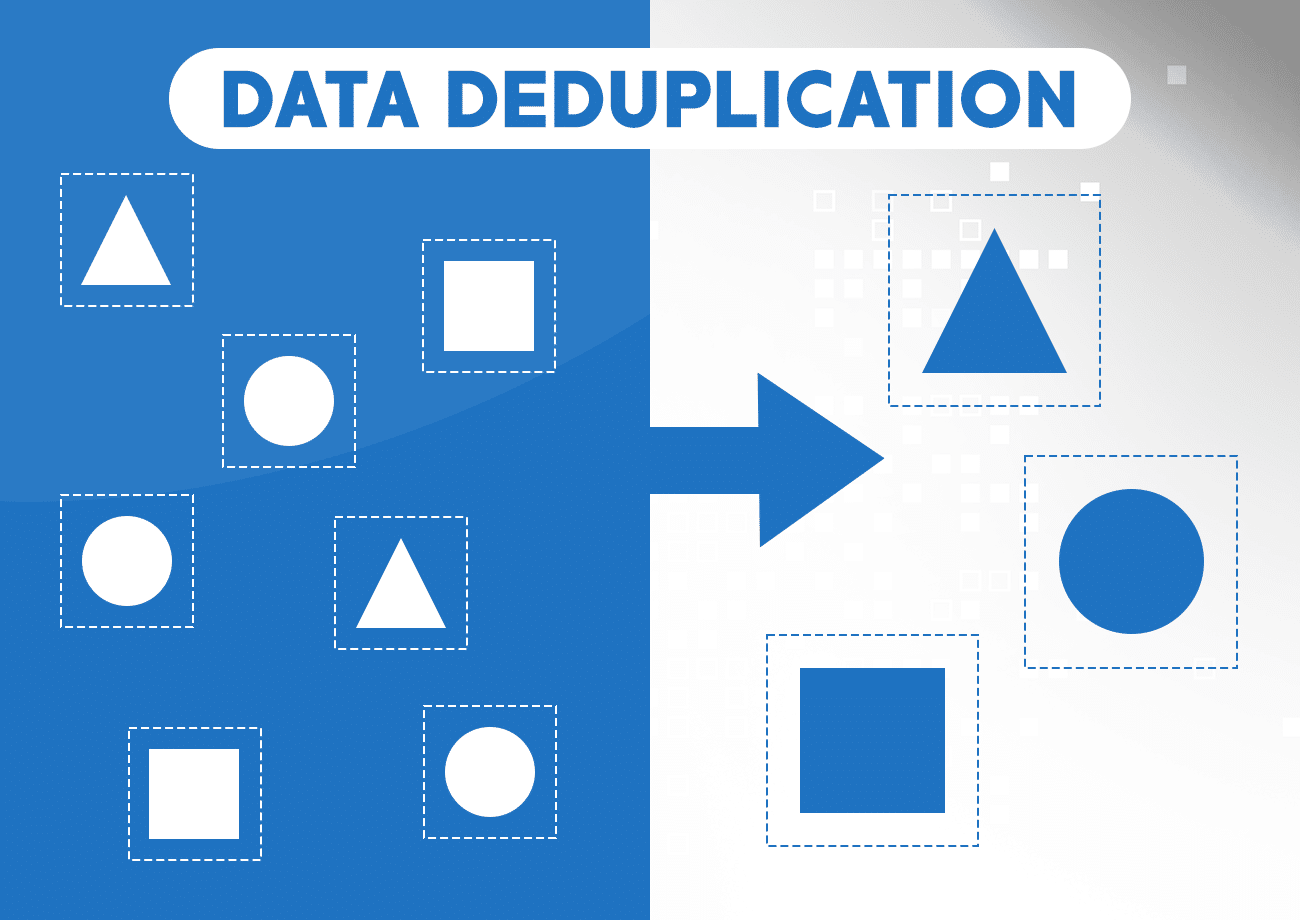
Deduplication refers to identifying and eliminating duplicate or redundant records within a certain dataset. This process involves comparing data entries and determining which records represent the same entity.
Additionally, there are two deduplication techniques you can implement to eliminate duplicate data:
Whichever technique you choose, the goal of deduplication is to ensure data accuracy, improve data quality, and prevent redundant or inconsistent information.

Entity resolution, also known as record linkage or entity matching, is the process of identifying and linking records that correspond to the same real-world entity across different data sources.
Thanks to entity resolution, you can determine if two or more records refer to the same individual, customer, or product.
Entity resolution techniques use various algorithms and similarity measures to compare data attributes and identify relationships or similarities between records.
The goal of entity resolution is to create a single, comprehensive view of an entity by linking and merging related records from disparate sources. This helps eliminate redundancy, consolidate information, and ensure data consistency and accuracy.
–
Overall, deduplication focuses on identifying and removing duplicate records within a dataset, while entity resolution aims to link and merge records representing the same real-world entity across different data sources.
Both processes are essential for achieving data quality, integrity, and a unified view of entities within a data management framework.
What happens if you don’t handle your data properly?
Real-world data is complex and has to be managed properly.
In the business context, not handling data properly can lead to serious consequences such as:
To help you understand the downsides of the poor MDM process, let’s look at one example.
A business has a centralized CRM solution that contains data about all of its customers. Over the years, the CRM has been filled with data from various sources such as:
Although most CRM solutions provide some form of duplicate handling, these processes mostly struggle with anything beyond basic rule-based deduplication and can perform only with limited amounts of data.
On top of this, even these basic processes could be skipped due to the origin and method of how the data was imported, human error, etc.
This could lead to having records such as those in the table below:
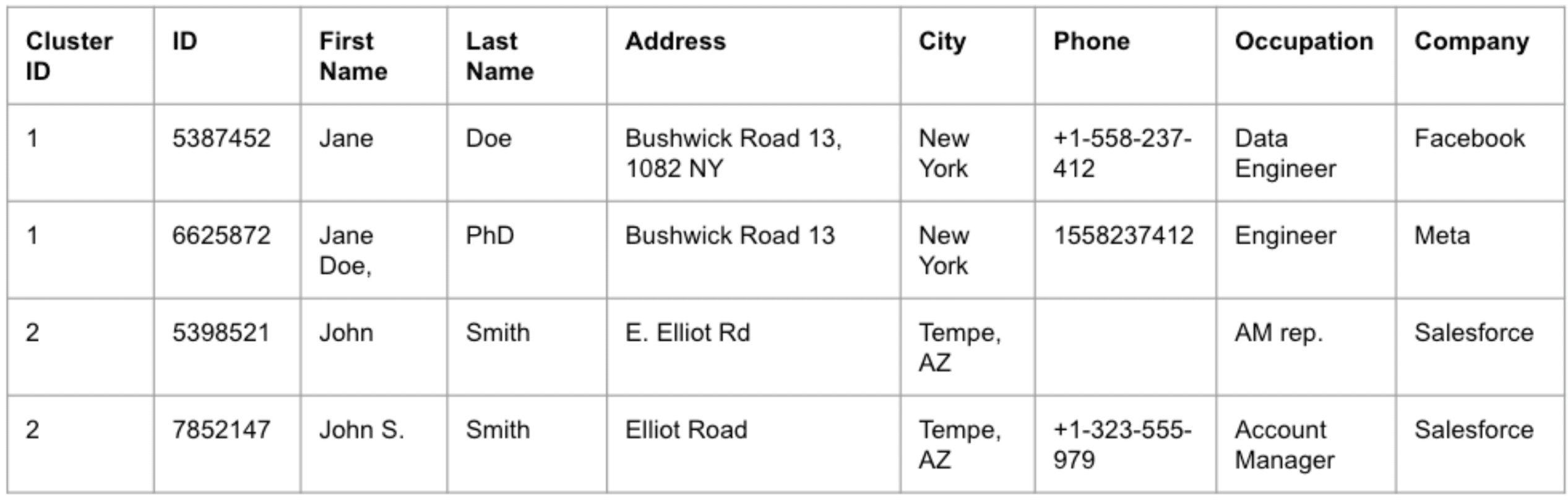
To the human eye, it is fairly obvious that we are dealing with two sets of duplicate records.
However, these customer records don’t share enough identical features which makes it really difficult to apply a simple rule-based process for deduplication and entity resolution.
Now imagine having a data set with hundreds of thousands or even millions of records – the complexity of the problem can rise exponentially.
So, how can you improve your MDM process and remove the possibility of duplicate records and redundant information?
If your company isn’t handling data in the right way, you can lose a lot of time, money, and ultimately customers. What you need instead is a suitable MDM approach based on data deduplication and entity resolution.
When we are talking about more effective data management, you should make sure to approach this from three different aspects:
Here are a few tips on how to address each aspect.
Connecting different data sources helps you gain a comprehensive and unified view of data. This also helps with facilitating accurate analysis and informed decision-making across your organization.
How can you connect disparate data sources?
These are some of the ways to connect disparate data sources. Now is the time to remove duplicates. Let’s see how.
Removing redundant and duplicate data is important because it can:
Here are a few tips to implement:
Hopefully, some of these tips will prove helpful to you. Let’s see what you can do to enrich your data.
This step is important because it enhances the value and quality of your information by incorporating additional relevant details, context, and external data sources.
Here are a few ideas:
Ultimately, successful data management should be based on a thoughtful strategy and the right tools. But you should also make sure to validate the quality and accuracy of your data before incorporating it into your MDM process.
If you truly want to maintain the integrity and usefulness of your data over time, you should conduct regular data maintenance, too.
At Things Solver, we know how hard it can be to find a suitable data management solution that handles data duplication effectively.
Imagine having 25% duplicate records in your datasets.
Now, stop and think about how much money you’re wasting on redundant communication with customers every month. Not only does this affect your budget, but it also leads to poor customer experience and negative brand perception. These 25% are impacting your critical reporting needs and your decision-making.
But, with our custom-made solutions, you could do much better.
Wanting to help businesses handle these data duplication and redundancy challenges easily, we have developed a unique model which handles it all with ease.
Our AI and ML-based entity resolution model has been tested against industry standards and achieved comparable or better results for a significantly lower cost.
It doesn’t require any adjustments to the data from the business side. It handles all the preprocessing, cleaning, and preparation autonomously.
All you need to do is provide the data – either from a single source or from multiple sources for cross-source matching.
Now, to make your MDM process seamless, you can additionally fine-tune our model:
Upon running the model, we’ll get clusters of related entities or duplicates. Depending on the specific problem we are addressing, you can determine whether you want:
The latter approach proves particularly valuable when dealing with data obtained from multiple sources, each containing different information. By consolidating these sources, we can create an enriched single record per entity, incorporating all available information.
There’s a reason why data deduplication and entity resolution are pivotal processes in the world of data management. They play a vital role in ensuring the accuracy, consistency, and reliability of information within an organization.
As data volumes continue to grow exponentially, the need to tackle data redundancy and inconsistencies becomes more pressing than ever before.
Together, data deduplication and entity resolution form a powerful duo that not only improves data quality but also drives business growth and profitability. By maintaining clean and clear data, you can enhance your data-driven initiatives, strengthen customer relationships, and optimize operational efficiency.
–
Ready to invest in a customized data management solution? With Solver’s tailor-made data management model, you can quickly position your business to stay ahead of the competition, adapt swiftly to changing market conditions, and unlock the full potential of your data assets. Contact us at ai@thingsolver.com and let’s come up with a solution that fits your needs.

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more