How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
25. 04. 2020.

We live in the era of information technology, when we generate more data in 10 minutes than the amount of total data generated from prehistoric times by the year of 2003. Having the processing power and memory resources to handle all this data being generated from different actors within different processes – organizations strive to utilize it in order to leverage their business – through process science and data science.
Process science is a wide discipline combining business management and IT, with the aim to optimize operational processes. By using operations management, stochastic, concurrency theory and workflow management together with business process management – process science deals with process optimization and enhancement.
In the business world, Data Science is all about data and turning it into real value. The possibilities are endless. Using predictive analytics for what-if scenarios and decision-making purposes has grown to be the essence of strategic planning. On the other side, advanced analytics is crucial for the optimization of operations pillars within the organization.
As you may see – process science is process-centric, while data science is data-driven. If you have ever thought that Data Science is extremely multidisciplinary – you have a long way to go, my dear friend. ?
Process mining is seen as “a means to bridge the gap existing between process science and data science”. By its nature, data science tends to be process agnostic, whereas process science tends to be process-oriented without considering the “evidence” hidden in the data. Process mining is both data-driven and process-centric.
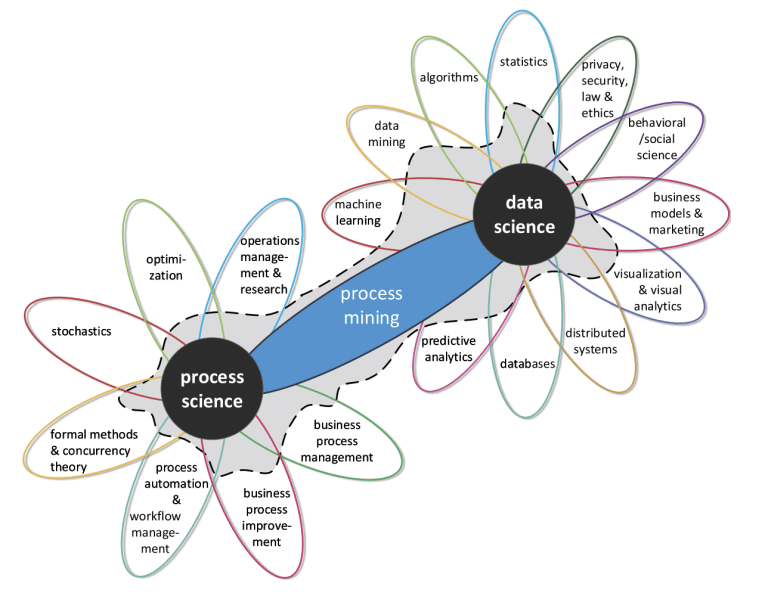
Process mining includes the analysis of event log data. These logs describe the behavior within some specified process. The behavior may be analyzed from different perspectives (contexts). On one side – process science techniques may be used to discover processes, check compliance, analyze bottlenecks, compare process variants and suggest improvements. On the other hand, data science techniques are used for pattern modeling and predictive analytics, in order to perform routing optimization by classifying cases, and/or predict total processing time, for example.
Process models are used for getting insights, verification, performance analysis, and configuration setup. However, there are several perspectives (contexts) that may be taken into account:
Process discovery is used for analyzing the process flow based on the activities reflected in event logs. Basically, by using process modeling techniques (like α-algorithm, for example) we can produce a process model without using any a-priori information.
Process conformance includes analyzing the fitness and/or deviations of real process cases to the defined (existing) process. In most cases – the idea is to point out all the bottlenecks within the process, in terms of the conformance (deviations) and performance (resources consumption).
Process enhancement includes process optimization by taking into account insights obtained from the process discovery and conformance phases, enriched with advanced analytics predictions and pattern detection. The main purpose of this phase is to propose improvements that should result in cost reduction, processing time optimization, efficiency increase, and customer satisfaction.
Establishing the relationship between the process model and reality can be performed by defining the relations in the following ways:
This is used for:
Let’s walk through one (heh, convenient) example. On the left side, you may see an ideal process of writing a blog post. One would say – just follow these steps, and you’ll get there. But, in reality, what really happens is that sometimes we’re not satisfied with the topic we have chosen, or we need more research, or we already know enough about the topic, so we can skip some steps, etc. In some (thankfully – rare) cases, we write a post which we never publish.
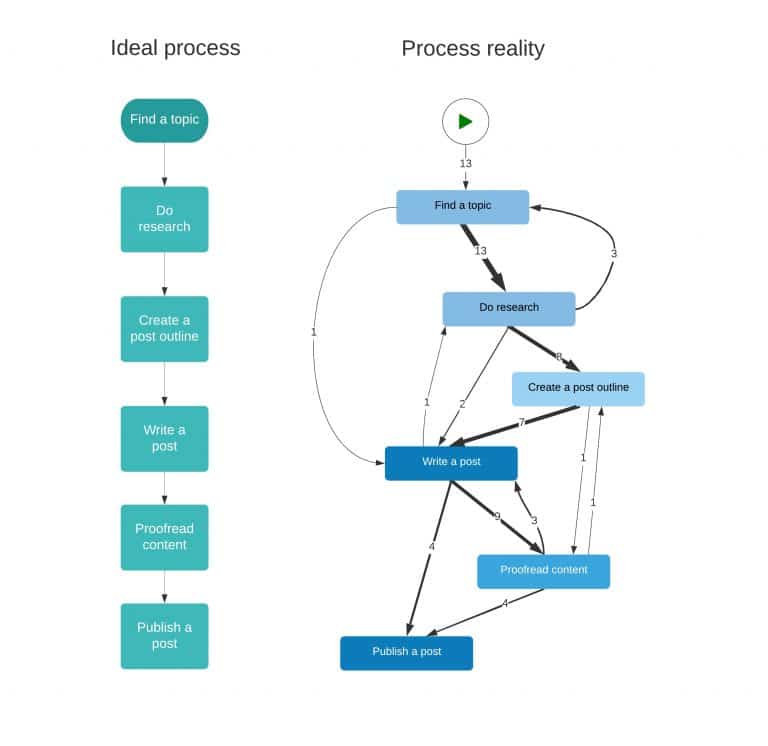
The idea is to analyze which steps are skipped, which are taken multiple times, understand why and propose another, more convenient approach, by taking into account insights obtained from the process mining analysis. One additional information that could also be analyzed here is the time spent in each of these phases. For example, maybe some blog posts take too much time to be published because the author has some problems regarding the language in which the post should be written, resulting in too much time spent in the “write a post” phase; or he may have skipped writing the outline and missed the overview, which resulted in not knowing where and how to start.
There are plenty of examples and issues that could be analyzed in this pretty much simplified process. Now imagine, for example, an organization having more than 100 employees, five different departments and more than ten different processes. I don’t know about you, but for me – it’s a treasury (for process mining). ?
Process mining is one of the ways in which organizations may successfully leverage their business processes, by using advanced analytics and machine learning, combined with discovery and conformance models. Being both process-centric and data-driven, process mining is an efficient way to increase performances, eliminate deadlocks, reduce costs, improve quality of service and optimize organizational resources.
If you’d like to learn more about process mining, I strongly encourage you to read this inspiring book – “Process mining – Data Science in Action”. It’s been written by professor Wil van der Aalst, godfather of process mining, and it served as the main inspiration for writing this blog post.
In a series of posts that follows, my dear colleagues and I will try to bring this discipline closer, and explain the functioning mechanisms of algorithms used within, in more detail. Cheers! ?
Cover photo taken from: https://unsplash.com/@jessbailey.

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more