Kako povećati online prodaju u ovoj prazničnoj sezoni uz personalizovano kupovno iskustvo
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
26. 01. 2019.

Kada se bavimo anomalijama u podacima, postoji mnogo izazova koje treba rešiti. Već smo imali nekoliko članaka na ovu temu, a ako ih već niste pročitali, predlažem vam da pogledate ovaj, i ovaj, od mog kolege Miloša. U ovom postu ću govoriti o jednom od mojih najvećih favorita među algoritmima za otkrivanje anomalija. Jednostavan je, superbrz i efikasan, sa malim zahtevima za memorijom i linearnom vremenskom složenošću. Neću da pričam o upotrebi, pošto sam naišao na odličan članak o Kretanju ka nauci podataka (pogledajte: Detekcija odstupanja sa algoritmom Isolation Forest). Ideja je da podelim svoje utiske, i da vas inspirišem da ga isprobate, i da mi date svoje mišljenje o tome.
Kao što možete pretpostaviti, Isolation Forest je metoda zasnovana na sastavljanju. A ako ste upoznati sa načinom na koji radi Random Forest (znam da jeste, svi ga volimo!), nema sumnje da ćete brzo savladati algoritam Forest algorithm. Pa, kako to funkcioniše?
Jedna stvar koju treba razjasniti pre objašnjenja algoritma je koncept „izolacije instance“. Dok većina drugih algoritama pokušava da modelira normalno ponašanje, da bi naučio obrasce profila, ovaj algoritam pokušava da odvoji anomalnu instancu od ostatka podataka (odatle pojam „izolacija“). Što je lakše izolovati instancu, veće su šanse da je anomalna. Kao što autori ovog rada sugerišu, većina postojećih pristupa detektovanju anomalija zasnovanih na modelu konstruiše profil normalnih instanci, a zatim identifikuje instance koje nisu u skladu sa normalnim profilom kao anomalije. Šta je problem u vezi sa tim? Pa, definisanje normalnog ponašanja. Granice normalnog ponašanja. U većini slučajeva, označavanje podataka i dobijanje informacija o normalnom i anomalnom ponašanju je preskupo i dugotrajno. I tada kreativnost iskorači i ispoljava se na sceni. Kreirati jednostavno ali rešenje koje se graniči sa genijalnošću (u redu, ovde sam malo pristrasan :D).
Dakle, u osnovi, Isolation Forest (iForest) funkcioniše tako što gradi ansambl „drveća“, nazvanog Izolaciona stabla (iTrees), za dati skup podataka. Određeno iTree je izgrađeno na funkciji, izvođenjem particionisanja. Ako imamo funkciju sa datim opsegom podataka, prvi korak algoritma je da nasumično izabere podeljenu vrednost iz dostupnog opsega vrednosti. Kada se odabere podeljena vrednost, počinje particioniranje – svaka instanca sa vrednošću obeležja nižom od vrednosti podele se rutira na jednu stranu stabla, dok se svaka instanca sa vrednošću obeležja većom ili jednakom od vrednosti podele rutira u suprotnoj strani drveta. U drugom koraku, bira se druga nasumična podeljena vrednost, van dostupnog opsega vrednosti za svaku stranu stabla. Ovo se radi rekurzivno sve dok se sve instance ne stave u terminalne čvorove (lišće) ili dok se ne ispune neki od kriterijuma postavljenih u ulaznim parametrima. Pojednostavljeni proces izgradnje stabla je prikazan ispod.
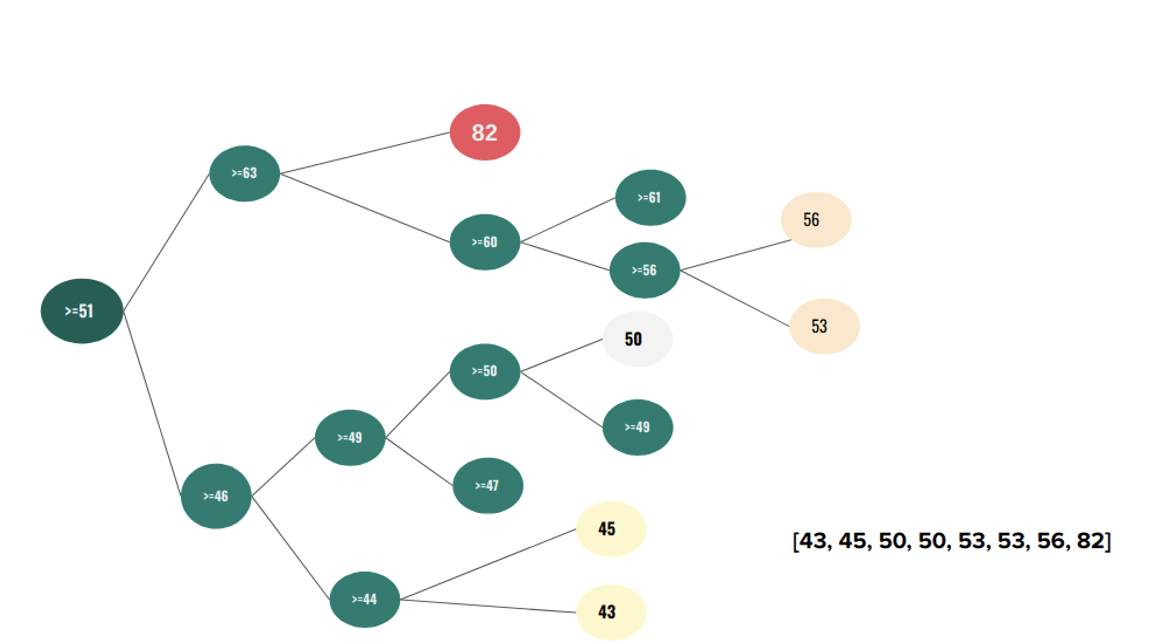
Ideja je jednostavna – ako se instanca lako izoluje (što znači da je preduzeto manje koraka da bi se smestila u terminalni čvor), ima veće šanse da bude anomalija. Sa slike koja sledi, može se primetiti da je Xi instanca iz gustog područja zahtevala mnogo koraka da bi bila izolovana, dok je usamljena Xo instanca zahtevala mnogo manje.
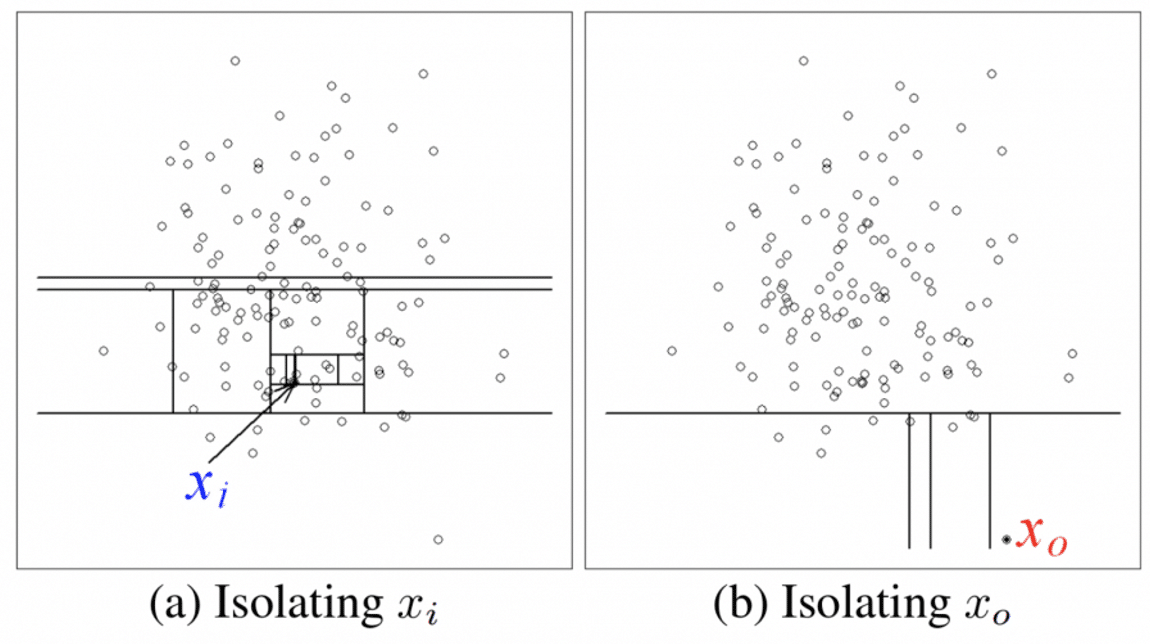
Dakle, u algoritmu iForest, rezultat anomalije je određen dužinom putanje od korenskog čvora do lista u kojem je instanca smeštena. Pošto je to ansambl, uzima se prosek svih dužina putanja za datu instancu. Može se indukovati da su prosečna dužina putanje i rezultat anomalije obrnuto proporcionalni – što je put kraći, to je veći skor anomalije. U slučaju da sam bio potpuno konfuzan, ostaviću samo zvaničnu dokumentaciju ovde.
Postoje dva glavna parametra – broj stabala i veličina poduzorkovanja. Veličina poduzorkovanja kontroliše veličinu uzorka koji će se koristiti iz obuke modela, kada se izvrši particioniranje. U zvaničnoj dokumentaciji, autori sugerišu da su empirijski utvrdili da su optimalne vrednosti za ove parametre 100 i 256, za broj stabala, odnosno veličinu poduzorka.
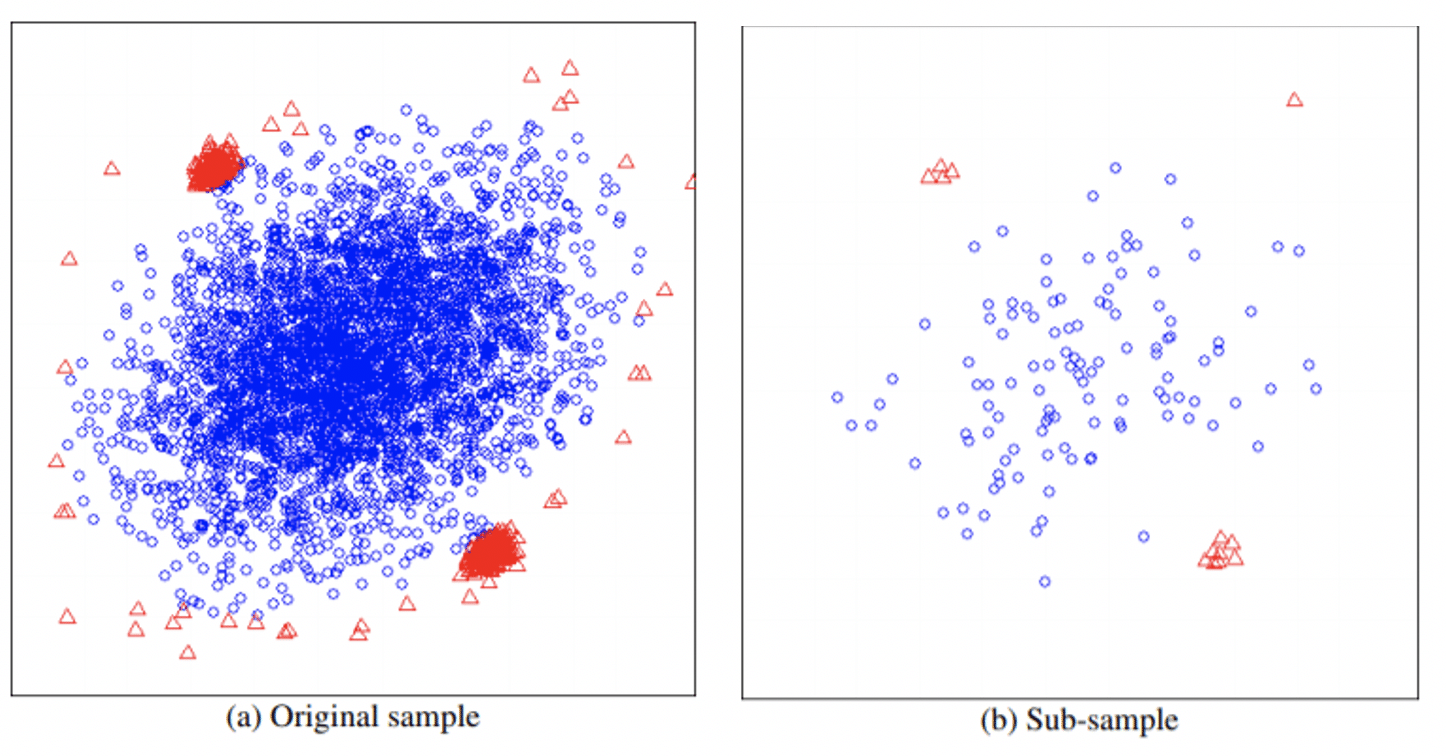
Sada, postoje dva glavna problema na koja se može naići kada se radi o otkrivanju anomalija: zatamnjenje i maskiranje. Swamping je situacija pogrešnog identifikovanja normalnih instanci kao anomalnih, što se može desiti kada su normalne i anomalne instance blizu jedna drugoj. Maskiranje je situacija pogrešnog identifikovanja anomalnih instanci kao normalnih, što se često dešava kada se zajedno nalaze u gustom području, tako da „prikrivaju“ svoje prisustvo. Poduzorkovanje u algoritmu iForest-u omogućava mu da napravi delimičan model koji je otporan na ova dva efekta. Sledeća slika pokazuje kako poduzorkovanje može lako da reši oba problema. Može se primetiti da je poduzorkovanje očistilo normalne instance oko klastera anomalija i smanjilo veličinu anomalnih klastera, što bi moglo dovesti do zahteva više koraka za izolaciju.
Scikit-learn implementacija ima neke dodatne parametre poput maksimalnog broja funkcija za razmatranje i kontaminaciju – procenat anomalija koje treba identifikovati, što je veoma lepo. U osnovi funkcioniše na takav način da se određeni procenat slučajeva sa najvećim rezultatom anomalije označi kao anomalan. Ima funkciju_odlučivanja () koja izračunava prosečnu ocenu anomalije i funkcije za prilagođavanje i predviđanje. I još nismo stigli do najveće prednosti algoritma! Može da radi i u nadziranom i u nenadziranom režimu, što ga čini zaista skrivenim herojem oblasti mašinskog učenja. Dakle, možete ga hraniti ili sa ulaznim podacima i oznakama, ili samo sa ulaznim podacima, on će ga „zgnječiti“ i vratiti izlaznu vrednost.
Da bismo smanjili pristrasnost, hajde da pričamo o nedostacima, jer su prisutni. Prvo i najvažnije – ne može da radi sa multivarijantnim vremenskim serijama, što je jedan od najvećih problema sa kojima se suočavamo u praksi. Što se tiče scikit-learn implementacije, jedna stvar koja me stvarno muči je to što nije moguće dobiti posebnu odluku za svako iTree. Osim toga, takođe je nemoguće vizuelizovati drveće, a, budimo iskreni – ljudi vole da vide sliku. Ništa im se ne dopada više od savršeno prikazanog algoritma koji mogu sami da protumače. Moglo bi biti zaista korisno videti koja karakteristika je izazvala anomaliju i kojeg intenziteta. Druga stvar koja me ovde brine je – kako će se ponašati sa karakteristikama koje su blago devijantne? Bojim se da to može dovesti do sličnih dužina putanje i do problema sa maskiranjem (ispravite me ako grešim). Konačno, nisam ga stvarno testirao sa kategoričkim podacima, ali ako neko ima iskustva sa tim, molim vas da mi kažete.
Što se tiče njegove prirode, Isolation Forest pokazuje zavidne performanse kada radi sa visokodimenzionalnim ili suvišnim podacima. Prilično je moćan kada je postavljen na odgovarajući način i za probleme koji ne zahtevaju otkrivanje kontekstualnih anomalija (kao što su vremenske serije ili prostorna analiza). A pošto je superbrz, stvarno volim da ga koristim. Isprobao sam ga na maloprodaji i na telekomunikacionim podacima, i rezultati su bili prilično zadovoljavajući.
Otkrivanje anomalija je i dalje jedan od najvećih problema sa kojima se analitičari susreću kada rade sa podacima. Nema sumnje da će biti više algoritama za otkrivanje anomalija u podacima, sa mnogo poboljšanja i mogućnosti. Ali najvažnije je da se ne zanemari značaj i uticaj anomalija na rezultate i donošenje odluka, jer one predstavljaju veoma osetljiv problem i njima treba pažljivo pristupiti i analizirati ih. Imajte to na umu. Hvala vam! [nz_icons icon=”icon-wink” animate=”false” size=”small” type=”circle” icon_color=”” background_color=”” border_color=”” /]

Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Praznična sezona je najvažniji period za trgovce Osim velikog obima prodaje, to je i prilika da ostavite trajan utisak na…
Read more
Detaljniji pogled na ono što AI analitika zaista znači Obučili ste svog AI agenta. Radi. Priča. Reaguje. Ali, da li…
Read more
Agentna veštačka inteligencija Zamislite da imate tim vrhunskih kuvara, ali vam je frižider pun pokvarjenih sastojaka. Bez obzira na to…
Read more