How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
29. 01. 2021.

I didn’t want to start this post by quoting the percentage of data science projects failing to deliver commercial value or business utilization. Many data science projects fail – and that’s a fact. What’s important is to make sure that you are not spending hundreds of Ks of euros/dollars? and other resources and fail.
Being successful at implementing data science, machine learning, data pipelines, data ops, in business is complex. And there are many prerequisites to successfully implementing such a project – ranging from operational and technical in terms of data availability and quality, lack of resources, to strategic and the focus of the organization to implement data products. We can refer to any product that aims to achieve the end goal through the use of data as the data product.
Over the years we had an opportunity to work on many interesting projects across industries. Many of them achieved great success and became industry awarded products (https://www.lightreading.com/artificial-intelligence-machine-learning/meet-sara-the-ai-that-may-be-a-big-deal-for-austrias-main-telco/d/d-id/755428). And some of them didn’t have the same destiny, and are not commercialized yet.
As time followed, we have tested different approaches for maximizing the outcome of our work, and have our data projects under control. The core value that we nurtured when it comes to implementing data products with our customers is fail-fast: test in early stages whether goals that we set could be achieved with the state of the current data landscape, and focus our energy on more important tasks if not. From the place where I’m currently standing, there is no better way, especially for new areas of analysis and research or companies that are new to the industry.
Throughout the years, I’ve had a chance to learn A LOT about different approaches to delivering data products to different industries – what should work, and what most definitely won’t. 🙂 In the following series, I will share our experiences and approaches (the ones that proved to work for us) that are incorporated in Things Solver DNA of how we deliver value from data to our customers.
And the first question that comes for any project you are working on – where’s the problem?
For any problem you are trying to solve, the crucial is to clearly understand if the problem is worth solving. This doesn’t go only for advanced analytics, it’s important for any task you are trying to accomplish. Doesn’t matter if your solution is the most brilliant in the history of the universe – unless it solves the problem worth solving, it’s useless.
Over the years, we played with different methodologies for defining a problem worth solving and identifying key determinators for it. It’s always important to ensure our customers are investing in something that will benefit them significantly. As a step to it, we have established a process of assessing the client’s data strategy as the first step. Throughout this phase, we are working closely with the customer’s team to identify their maturity and data proficiency, and enlist all the potential use cases they can think of – without going into details about how achievable and realistic those are. The main goal is for different departments to get creative, and think deeply about their core business challenges and goals that should be achieved. While working on identifying potential use cases, it is crucial for us to gather stakeholders from various backgrounds – depending on the industry we typically aim to include Business Development, CRM, Marketing and Sales, technical managers, finance, customer service, and operations managers – depending on the area we are aiming to address. Working with different industries over the years enabled us to understand the main challenges and opportunities for many businesses, which helps us to guide stakeholders during these workshops and help them focus. This also helped us identify a common set of goals companies aim to achieve, and voila – our first product – Solver AI Suite was born.
At this stage of finding a perfect problem to solve, we focus mostly on guiding our customers and help them be creative, and not try to impose our own opinions. Customers should be able to focus on what really matters for their business, without us being subjective in terms of the tasks we would very much like to work on or we find them important based on our experience with other customers. 🙂 On the other hand, experience across industries helps a lot in the advisory role.
This part of the process is very creative and fun. But since this is a starting point from where the true value for the business is created, it is crucial for it to be well structured, planned and guided. At this stage we aim to cover the whole business strategy of a company, so it can be quite exhaustive – we typically split it into multiple well structured and prepared workshops.
Once we have a clear list of goals to be achieved and problems to be solved, we go into prioritizing their implementation and making a roadmap for the organization to achieve them – finding the perfect first to start with. Two crucial measures should come out of this process – Impact and Effort.
How impactful each use case is for the overall strategy and operations of the business? At the end of the day, this is how any project should be measured – how much better my business will be after I implement this? It’s always great if you can focus on things that matter the most, and help achieve goals of the highest impact. In order to measure the impact objectively, it’s important to have different teams included – our goal is to see how impactful resolving each problem is for the whole organization.
Our 2nd goal for this step is identifying how well aligned are different business units in terms of overall company goals and who are the key stakeholders in the process. With that in mind, we can understand a problem more clearly, but also how different teams communicate related to different processes and daily operations, and what’s their role. It’s also a safeguard not to miss to include all the relevant stakeholders in the process.
How much effort and resources are needed to achieve these goals? Prioritization is important in terms that we want to always focus on topics that matter the most. But effort estimation comes in neatly to ensure that we can deliver value without spending months or years while working on a single use case – important tasks that require less effort in most cases are our priority.
In this phase, it’s very important to take into consideration the existing data landscape in the organization – data points that exist, their quality and availability, internal and external data management policies, etc. Many years of experience that we have working with different industries on different use cases, enables us to more objectively look at the complexity of dozens of use cases, and in cooperation with the client identify which goals can be achieved in the short term, and which use cases require many stages to enable their implementation.
What we always advise our customers is to focus on challenges that bring a significant impact to the business without too much effort. This is especially important for organizations that are new to advanced analytics, and are just starting to implement use cases in this domain. With this approach, we aim to make the whole organization a believer in machine learning – we aim to get impactful results really fast so that with the key stakeholders, we can get the needed support from the whole company to invest their effort and resources in this area. Low hanging fruit is generally a good idea for newcomers to aim for when just starting experimenting in machine learning and AI. It helps to understand the process, the way of work, and the methodology, and prepare the team for bigger challenges.
Identifying effort is more challenging than identifying impact in most cases – there are many variables that need to be taken into account, and in many cases it requires a few iterations from both sides – our and customer’s – to determine it. We aim to measure factors like data availability and quality, our and client’s previous experience in the area, similar or planned projects in the area, the complexity of the analysis itself, … Crucial is to oversee which blockers may exist and how we can overcome them. Usually it may arise that the data needed for such analysis is either not available or not of required quality, so we have to make a plan of how we can provide it.
Estimating any task is very complex, and additionally with data science we are never able to tell whether something will work 100% – at the end it depends on the data and processes and behaviors that data describes. Over or underestimating shouldn’t be a dealbreaker if we have a process under control and we are able to adapt to changes and new facts.
Once we are able to estimate the effort required per each use case, we can proceed to building a roadmap to achieving all the identified goals. As the outcome, we want to determine different sets of use cases:
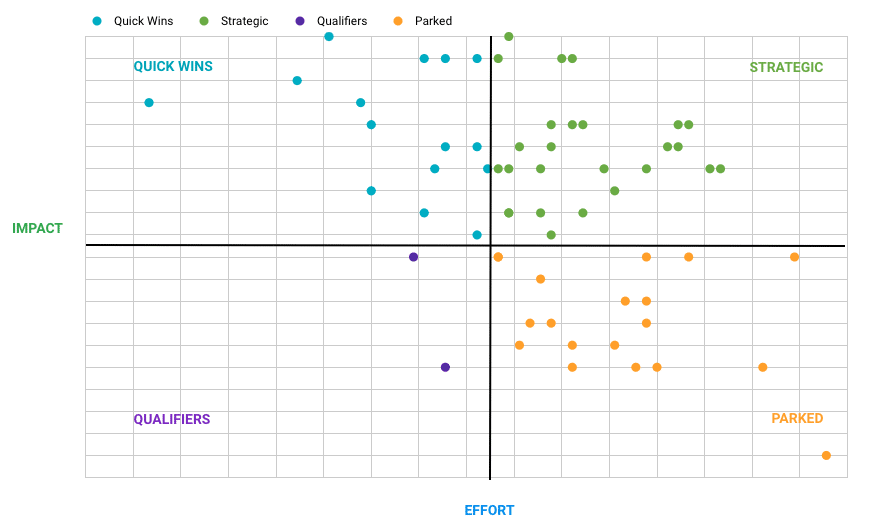
We are aiming to prepare a roadmap to achieve all of the identified goals (please note – a roadmap, not a plan). What’s truly important for any organization is to revise their use cases, impact, effort, and the roadmap frequently – at least once a quarter – since business landscape, strategy and main goals may change.
Once we are satisfied with the results of our ideation, we go to the last stage in Problem Definition – defining a scope. Scoping has to start with specific business needs and objectives from the list of use cases – which we can measure. A primary question we should ask ourselves is which actionable insights we are getting as the outcome, and how do they fit the current business landscape.
Any scope should cover two really important dimensions:
It’s a good practice to try to summarize the scope in a single specific sentence – although everyone is aware of the multiple milestones, subgoals and touchpoints to be made down the road – another addition to a clearly defined scope.
As someone who is in charge of achieving these objectives, we have to focus on the data points we need and the analysis and methodologies we aim to perform.
By taking into account data points, product requirements, relevant business processes and work required to be performed for the planned scope, we are able to identify which skills and roles are needed to accomplish the goals – data engineers, data scientists, UI/UX designers, frontend and backend developers, data ops to manage pipelines, etc.
The whole process of defining and scoping a perfect data science problem should be heavily data informed to define a realistic project scope and set realistic expectations.
For us internally at Things Solver, the whole process helps us to determine our offering for achieving the goals – do and to what extent our products and services fit into the landscape – at the end of the day are we a good match for achieving them.
After going through the whole process of brainstorming, collecting data, revising business plans and strategies, teams and processes, use cases and requirements, heavily communicating inside and across of the teams, integrations and flows, defining milestones and subgoals, … – we get The Scope. The Scope determines the start, the flow and the destiny of the project.
This is where our project starts. 🙂
Photo credits: https://www.pexels.com/photo/black-and-white-dartboard-1552617/

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more