How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
13. 01. 2021.

Over the last few decades, recommender systems have gained prominence with the emergence of platforms like YouTube, Amazon, and Netflix.
These algorithms play a pivotal role in suggesting relevant content for online users – from e-commerce product recommendations to personalized online ads.
In this guide, we’ll:
Let’s start!
First things first, let’s define recommender systems.
Recommender systems are sophisticated algorithms designed to provide product-relevant suggestions to users.
Recommender systems play a paramount role in enhancing user experiences on various online platforms, including e-commerce websites, streaming services, and social media.
Essentially, recommender systems aim to analyze user data and behavior to make tailored recommendations.
This is how they work:
Now that we’ve learned how recommender systems work, let’s explore the basic types of recommenders – non-personalized and personalized.
Non-personalized recommendation systems provide recommendations to users without taking into account their individual preferences or behavior.
These systems make recommendations based on the characteristics of items or content themselves rather than relying on user-specific data.
A popular non-personalized recommender is the popularity-based recommender which recommends the most popular items to the users, for instance:
However, non-personalized recommendation systems have their limitations, including the inability to provide highly tailored recommendations. They may be a good option for a first step in the process of personalization, but you shouldn’t stop there.
Once you gather enough data about the user in question, personalized offers and recommendations are the logical next step.
This is especially important if you don’t want to reject your potential buyer by failing to recognize what they like and what to recommend next. Or even worse, you recommend a product they have already bought.
This can all be handled well with a suitable personalized recommender system.
Personalized recommendation systems are designed to provide tailored recommendations to individual users based on their past behavior, preferences, and demographic information.
Based on the user’s data such as purchases or ratings, personalized recommenders try to understand and predict what items or content a specific user is likely to be interested in. In that way, every user will get customized recommendations.
At this point, you might ask yourself – what makes a good recommendation?
Well, a good recommendation:
There are a few types of personalized recommendation systems, including content-based filtering, collaborative filtering, and hybrid recommenders.
Let’s explore them in greater detail.
Personalized recommender systems can be categorized into several types, each with its own methods and techniques for providing tailored recommendations.
These include:
Content-based recommender systems use items or user metadata to create specific recommendations. To do this, we look at the user’s purchase history.
For example, if a user has already read a book from one author or a product from a certain brand, you assume that they have a preference for that author or that brand. Also, there is a probability that they will buy a similar product in the future.
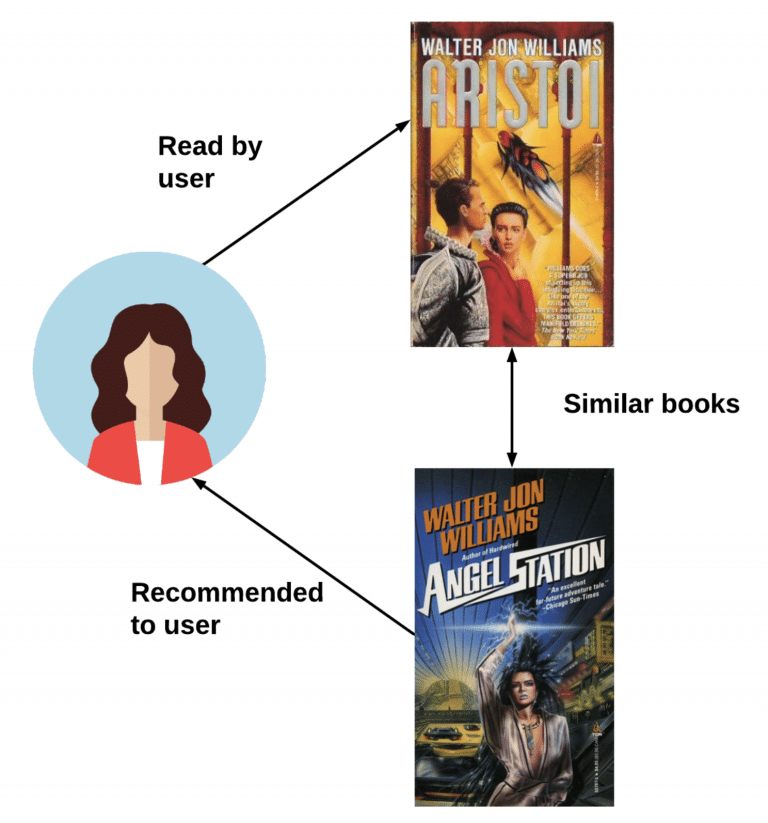
Let’s assume that Jenny loves sci-fi books and her favorite writer is Walter Jon Williams. If she reads the Aristoi book, then her recommended book will be Angel Station, also a sci-fi book written by Walter Jon Williams.
This is what content-based filtering looks like in real life.
The content-based approach is one of the common techniques used in personalized recommendation systems. It has its advantages and disadvantages, which are important to consider when deciding to implement this approach.
Let’s take a look at some of its most obvious advantages first:
On the other hand, the content-based approach can come with a few disadvantages, too. These can include:
Collaborative filtering is a popular technique used to provide personalized recommendations to users based on the behavior and preferences of similar users.
The fundamental idea behind collaborative filtering is that users who have interacted with items in similar ways or have had similar preferences in the past are likely to have similar preferences in the future, too.
Collaborative filtering relies on the collective wisdom of the user community to generate recommendations.
There are two main types of collaborative filtering: memory-based and model-based.
Memory-based recommenders rely on the direct similarity between users or items to make recommendations.
Usually, these systems use raw, historical user interaction data, such as user-item ratings or purchase histories, to identify similarities between users or items and generate personalized recommendations.
The biggest disadvantage of memory-based recommenders is that they require a lot of data to be stored and comparing every item/user with every item/user is extremely computationally demanding.
Memory-based recommenders can be categorized into two main types user-based and item-based collaborative filtering.
User-based
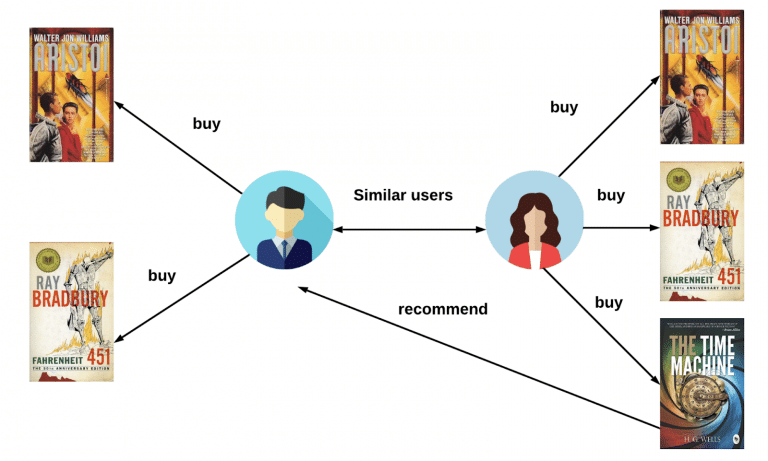
With the used-based approach, recommendations to the target user are made by identifying other users who have shown similar behavior or preferences. This translates to finding users who are most similar to the target user based on their historical interactions with items. This could be “users who are similar to you also liked…” type of recommendations.
But if we say that users are similar, what does that mean?
Let’s say that Jenny and Tom both love sci-fi books. This means that, when a new sci-fi book appears and Jenny buys that book, that same book will be recommended to Tom, since he also likes sci-fi books.
Item-based
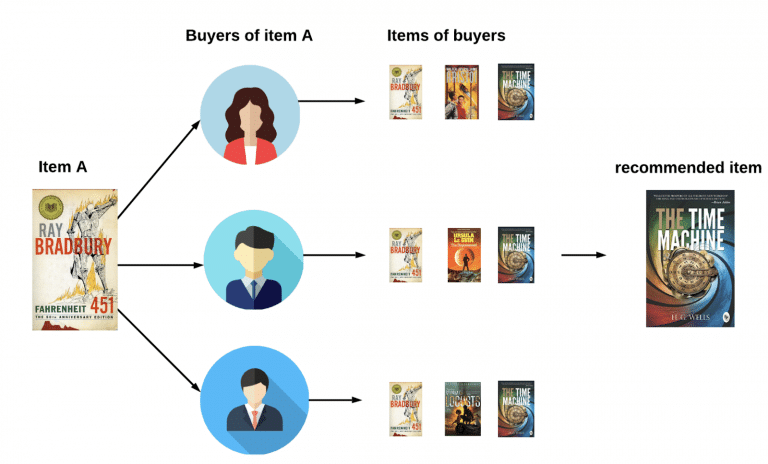
In item-based collaborative filtering, recommendations are made by identifying items that are similar to the ones the target user has already interacted with.
The idea is to find items that share similar user interactions and recommend those items to the target user. This can include “users who liked this item also liked…” type of recommendations.
To illustrate with an example, let’s assume that John, Robert, and Jenny highly rated sci-fi books Fahrenheit 451 and The Time Machine, giving them 5 stars. So, when Tom buys Fahrenheit 451, the system automatically recommends The Time Machine to him because it has identified it as similar based on other users’ ratings.
Unlike the content-based approach where metadata about users or items is used, in the collaborative filtering memory-based approach we are looking at the user’s behavior e.g. whether the user liked or rated an item or whether the item was liked or rated by a certain user.
For example, the idea is to recommend Robert the new sci-fi book. Let’s look at the steps in this process:
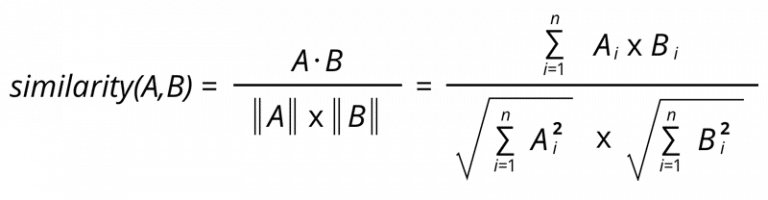
The item-item similarity calculation is done in an identical way and has all the same steps as user-user similarity.
The similarity between items is more stable than the similarity between the users.
Why?
Well, a math book will always be a math book, but a user can easily change his mind – something they liked last week might not be interesting next week.
Moreover, there are fewer products than users. This means that an item-item matrix with similarity scores will be smaller than a user-user matrix.
Finally, an item-based is a better approach if a new user visits the site while the user-based approach is problematic in that case since you don’t have enough or any data at all (the cold-start problem).
Model-based recommenders make use of machine learning models to generate recommendations.
These systems learn patterns, correlations, and relationships from historical user-item interaction data to make predictions about a user’s preferences for items they haven’t interacted with yet.
There are different types of model-based recommenders, such as matrix factorization, Singular Value Decomposition (SVD), or neural networks.
However, matrix factorization remains the most popular one, so let’s explore it a bit further.
Matrix factorization is a mathematical technique used to decompose a large matrix into the product of multiple smaller matrices.
In the context of recommender systems, matrix factorization is commonly employed to uncover latent patterns or features in user-item interaction data, allowing for personalized recommendations. Latent information can be reported by analyzing user behavior.
If there is feedback from the user, for example – they have watched a particular movie or read a particular book and have given a rating, that can be represented in the form of a matrix. In this case,
Since it’s almost impossible for the user to rate every item, this matrix will have many unfilled values. This is called sparsity.
Matrix factorization aims to approximate this interaction matrix by factorizing it into two or more lower-dimensional matrices:
The rating matrix is a product of two smaller matrices – the item-feature matrix and the user-feature matrix. The higher the score in the matrix, the better the match between the item and the user.
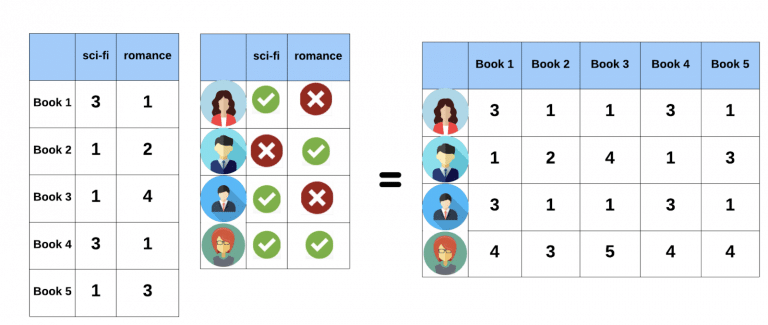
The matrix factorization process includes the following steps:
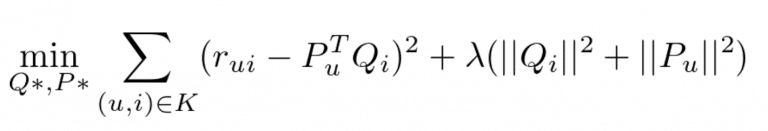
Looking at the bigger picture, collaborative filtering comes with a set of great advantages:
It’s important to note that while collaborative filtering offers these and other advantages, it also has its limitations, including:
To address these and other limitations, recommendation systems often use hybrid approaches that combine collaborative filtering with content-based methods or other techniques to improve recommendation quality in the long run.
Hybrid recommendation systems combine multiple recommendation techniques or approaches to provide more accurate, diverse, and effective personalized recommendations.
They are particularly valuable in real-world recommendation scenarios because they can provide more robust, accurate, and adaptable recommendations.
The choice of which hybrid approach to use depends on the specific requirements and constraints of the recommendation system and the nature of the available data.
Some of the most common advantages of hybrid recommenders include:
Just like all other recommenders systems, hybrid recommenders have their downsides, too. Some include:
While hybrid recommenders offer significant advantages in terms of recommendation quality and versatility, you should carefully consider the trade-offs and resource requirements when deciding which system to implement.
This is the best way to ensure that the benefits of hybridization outweigh the added complexity and costs.
To assess the performance and effectiveness of recommender systems, you have to take into consideration certain evaluation metrics.
They can help you measure how well a recommendation algorithm or model is performing and provide insights into its strengths and weaknesses.
There are several categories of evaluation metrics, depending on the specific aspect of recommendations being assessed.
Some common evaluation metrics include:
You can also choose to look at some business metrics such as conversion rate, click-through rate (CTR), or revenue impact. But, ultimately, the best way to do an online evaluation of your recommender system is through A/B testing.
Which metric will be used depends on the business problem being solved.
If we think that we have made the best possible recommender and the metric is great, but in practice it is bad, then our recommender is not good. For example, Netflix’s recommender was never used in practice because it didn’t meet customer needs.
The most important thing is that the user gains trust in the recommender system. If we recommend to them the top 10 products, but only 2 or 3 are relevant to them, they will consider this a bad recommendation.
For this reason, the idea is not to always recommend the top 10 items but to recommend items above a certain threshold.
Although quite helpful and effective in providing personalized recommendations, recommender systems encounter several real-world challenges.
One significant challenge is the “cold start problem,” which arises when a new user joins the system, and there is limited data available about their preferences.
In such cases, recommender systems can initially recommend either the top 10 best-selling products or the top 10 products on promotion as a starting point. Alternatively, conducting user interviews can help gather information about the user’s preferences.
Another aspect of the cold start problem pertains to introducing new products to users. This can be achieved by leveraging content-based attributes and periodically adding new products to user recommendations while actively promoting them.
Furthermore, churn poses another challenge, as users’ preferences and behaviors evolve over time. To address this, recommender systems should incorporate a degree of randomization to refresh the top N list of recommended items periodically.
It is also crucial to ensure that recommender systems are designed with sensitivity in mind, avoiding content that may offend or discriminate against users.
This includes steering clear of recommending items containing vulgar language, religious or political content, or references to drugs.
By tackling these challenges thoughtfully, recommender systems can enhance user satisfaction and provide meaningful recommendations while upholding ethical considerations.
Before deciding on the type of recommender system to implement, you should conduct a comprehensive analysis and consider several key factors.
First and foremost, you should define the metric you’re trying to maximize with the recommender system. Start by identifying your primary objectives and understanding what constitutes a valuable recommendation, as well as how to measure its success. This initial step provides a clear foundation for evaluating recommender options.
Next, you should account for technical limitations and resource requirements associated with each recommender. Some systems may demand significant computational power and data storage, while others may be more lightweight. This consideration directly impacts the feasibility and scalability of the chosen recommender.
Another critical aspect to consider is the method of recommendation delivery. Recommenders can:
For instance, real-time systems can recommend the next item to visit based on the user’s current session and browsing history. This choice influences the user experience and the system’s responsiveness.
Deciding what recommender system to choose should be a well-thought-out decision. Taking these considerations in mind, you can make informed choices that align with your goals and resources, but also enhance user satisfaction and system performance.
Future trends in recommender systems are shaped by emerging technologies, user preferences, and the evolving landscape of e-commerce, content streaming, and personalized services.
Here are 3 key future trends in recommender systems.
The future of recommender systems will see continued advancements in artificial intelligence (AI) and machine learning (ML) techniques.
These systems will become more sophisticated in understanding user preferences, behaviors, and contextual information. Deep learning models, reinforcement learning, and natural language processing will be leveraged to provide more accurate and personalized recommendations.
Thanks to these advancements, recommender systems will be able to understand complex user patterns and ultimately provide enhanced user engagement and satisfaction.
In a few years, we could be getting great recommendations from chatbots and have them become our online personal shopping assistants!
With the increasing focus on user privacy and data protection regulations (such as GDPR and CCPA), future recommender systems will need to prioritize user privacy and control.
Personalization will probably evolve to be more transparent and user-driven. Users will have greater control over their data and preferences, and recommender systems will need to operate within strict privacy constraints.
Techniques like federated learning, differential privacy, and user-centric data management will become integral to ensuring that both personalization and privacy coexist in harmony.
Recommender systems will no longer be confined to solely e-commerce platforms. They will find applications in a wide range of industries, including healthcare, entertainment, education, and more.
How can they be of help in other industries?
The versatility of recommender systems will probably facilitate their adoption across various domains and turn them into a fundamental part of the decision-making process in many industries.
These trends reflect the ongoing evolution of recommender systems. Whether you like it or not, they are here to meet the demands of users and provide more personalized and relevant recommendations.
As you’ve probably understood by now, recommender systems play a pivotal role in enhancing user experiences and driving business success.
These systems not only provide users with personalized experiences, but they also make it easier for you to build a strong brand, foster loyalty, and increase engagement and satisfaction.
From a purely business perspective, recommender systems hold the potential to boost revenue and profitability significantly. They can achieve this in different ways – but one thing is clear. By offering users precisely what they need or desire, you can create a competitive edge and remain relevant in a rapidly evolving digital landscape.
The truth is that we can’t stress the benefits of implementing recommender systems enough. Don’t wait any longer to start working on a unique strategy that works for your business. If you have any questions about this topic or you need help understanding further how recommenders fit into your long-term business plan, contact us at ai@thingsolver.com so we can discuss this on a more detailed level!

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more