How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
14. 05. 2021.
In this text we will try to briefly explain IM applications integration with Visual Search. You can read more about Visual Search implementation in our last blog post.
Among all other benefits, The Internet has transformed and simplified how people communicate with each other. In addition to email, IM has played a large role in bringing people together. From ICQ to MSN, Facebook Chat to Viber and WhatsApp, Internet users have been able to send messages to each other instantaneously for years. In the digital age, instant messaging is the easiest way to communicate with other people. No wonder our clients were very interested in this type of communication and integrations with different types of popular chatbots. Chatbot is a type of the Internet bot (web robot, robot or simply bot) that can simulate real conversations with people through instant messaging apps.
Rakuten Viber is a cross-platform Voice over Internet Protocol (VoIP) and instant messaging (IM) software application operated by Japanese multinational company Rakuten, provided as freeware for the Android, iOS, Microsoft Windows, macOS and Linux platforms. Users are registered and identified through a cellular telephone number, although the service is accessible on desktop platforms without needing mobile connectivity. In addition to instant messaging it allows users to exchange media such as images and video records. As of 2018, there are over a billion registered users on the network.
In Viber, bots can be created very simply via a bot user token that can access multiple Viber’s APIs (https://developers.viber.com/docs/api/):
Let’s see how Viber bot works:
1. Sending image for recommendation:
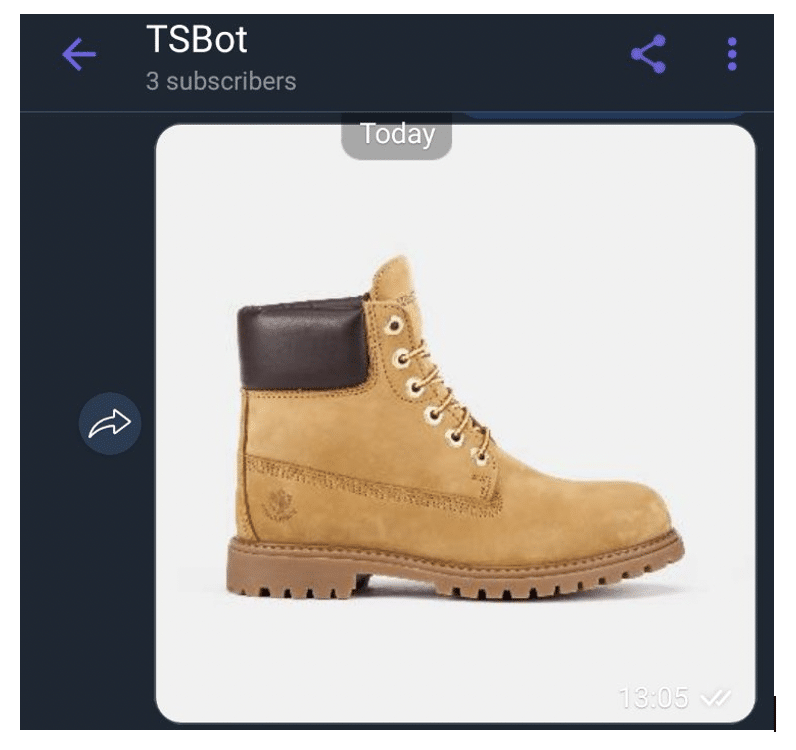
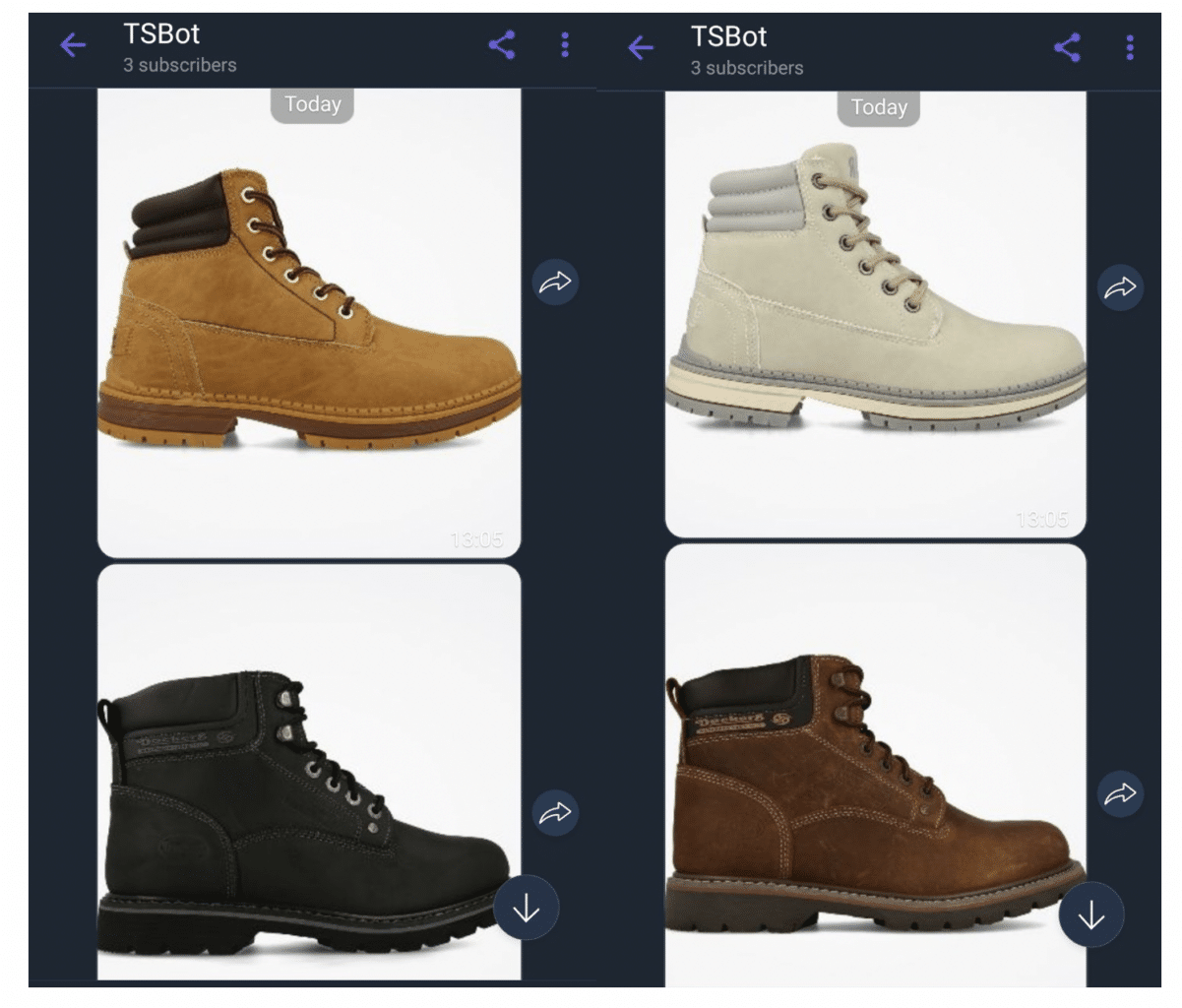
2. Viber bot is sending recommendations instantly:
Telegram is a freeware, cross-platform cloud-based instant messaging, video calling, and VoIP service. It was initially launched for iOS on 14 August 2013 in Russia, and is currently based in Dubai. Official Telegram client apps are available for Android, iOS, Windows, macOS and Linux, as well as for the now-discontinued Windows Phone.
How do I create a bot?
There’s a… bot for that. Just talk to BotFather (@botfather). You just need to log in in Telegram, search for @botfather and there you can find all other steps. Telegram APIs – https://core.telegram.org/bots
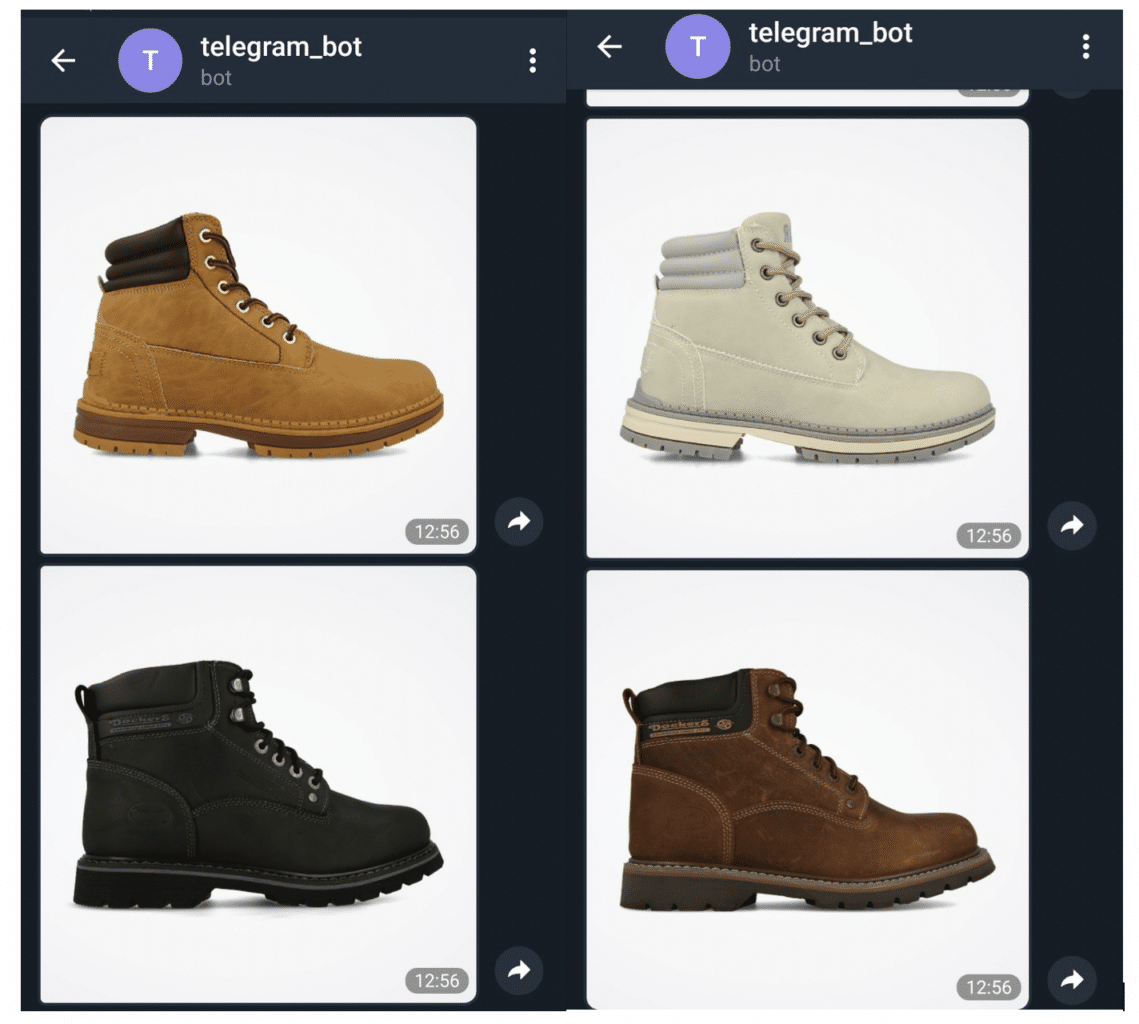
Let’s see how Telegram bot works:
1. Sending image for recommendation:
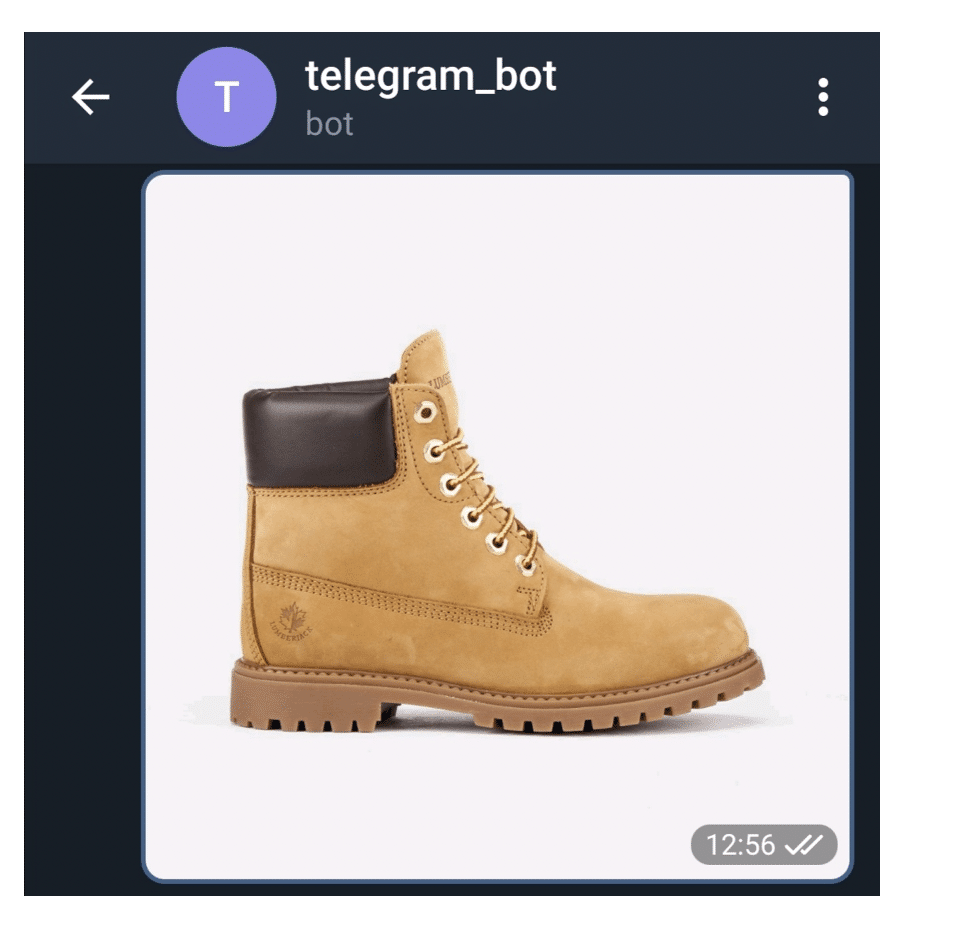
2. Telegram bot is sending recommendations instantly:
Slack (“Searchable Log of All Conversation and Knowledge” is an backronym for “Slack”) is a business communication platform launched in 2013, and developed by American software company Slack Technologies. It offers many features, including persistent chat rooms (channels) organized by topic, private groups, and direct messaging.
In Slack, a bot is controlled programmatically via a bot user token that can access one or more of Slack’s APIs – https://api.slack.com/ . ?
What can Slack bots do?
Let’s see how Slack bot works:
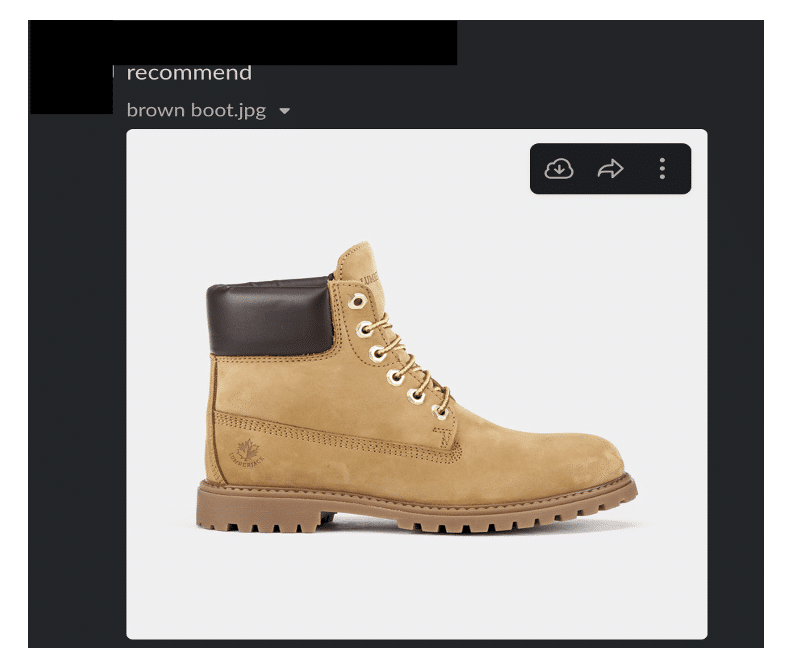
1. Sending image for recommendation with “recommend” text:
2. Slack bot is sending recommendations instantly:

As you can see, it’s not that hard to create and test simple bot applications like we did for Viber, Telegram and Slack. All you need is a test server and well documented API for the bot you want to use. ?
Photo credits: https://unsplash.com/photos/GWkioAj5aB4

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more