How to boost online sales this holiday season with a personalized shopping experience
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read moreThings Solver: Agentic AI + Customer 360 + Data Management
14. 10. 2020.

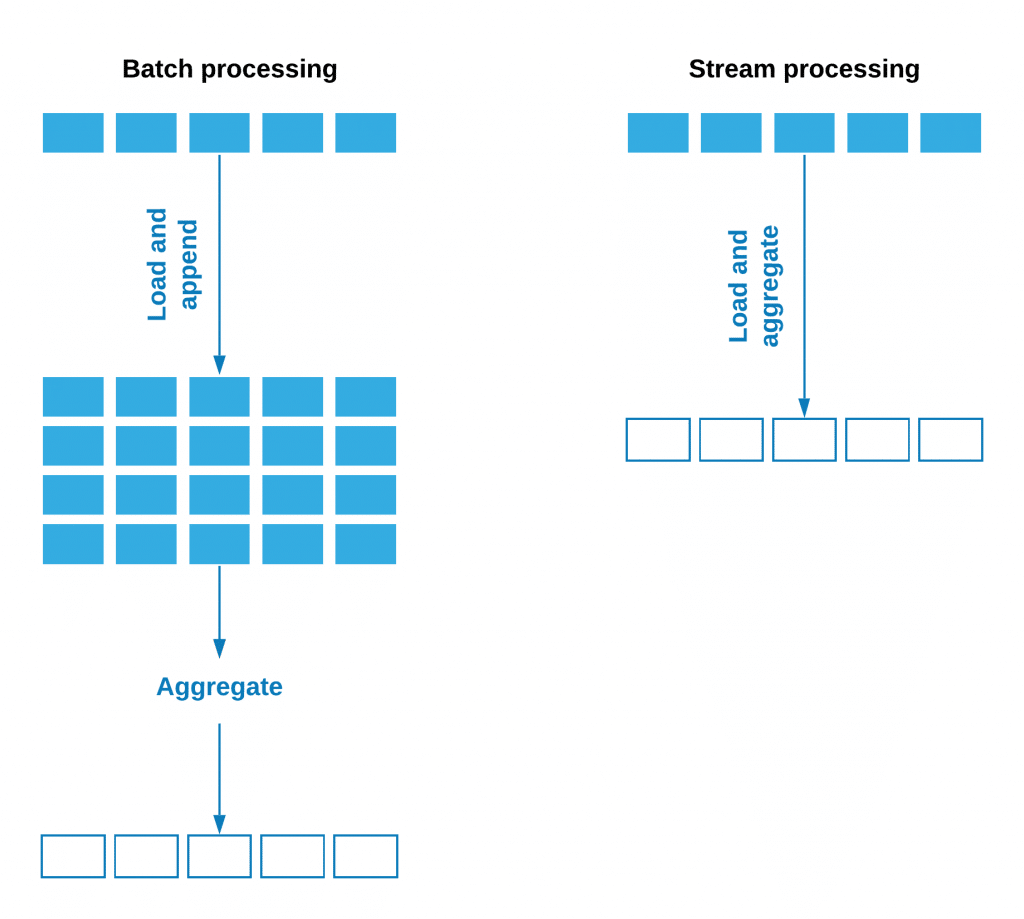
Data streaming has become very popular in the big data industry. It is used for processing large amounts of data from different sources which are continuously generated, in real-time. When we say “real-time” we need to understand that it can vary from a few milliseconds to a few minutes.
Besides that streaming is enabling us processing and enrichment in real-time, it also improves performances significantly. A set of data from a certain period of time is grouped into a batch, and when processing such a set, problems with memory and storage can occur.
In stream processing, micro-batches are generated and arrive in milliseconds, then certain conditions are determined, based on which we can take the foreseen steps. Once the micro-batches have passed through a stream that consists of loading, transformation, and eventual aggregations and conditions, data disappears from memory.
The conclusion is that we can work to process a much larger amount of data on cheaper hardware if the appropriate tool is selected and the quality processing is set up.
Latency is the time period between activity at source, and this can be a transaction, a weblog, an activity at a base station or networks, until the time when the data is stored in the appropriate form.
The latency level, or delay that we can accept, depends on the type of application we are working on and the use case. Therefore, when choosing a real-time data processing tool, the first precondition is that the latency obtained by choosing a particular tool is no longer than the delay that we can tolerate. For example, security and fraud detection are some of the case-case examples that do not tolerate a great latency period.
Event time is the time when some transactions happen. Processing time is the time when it’s processed inside our job. In an ideal world without any latency or delay, those two timestamps should be the same. Unfortunately, that’s hardly possible, but we tend to lower the gap between them.
Joining in batch processing is mostly a trivial thing, but in streaming, it’s not that straightforward. If you want to join the stream part of your flow with some static table, it’s gonna be pretty much the same as batch joining, however, if you tend to join two streams, things are getting complicated. Because of this, it’s really important to give special attention to datetime records to avoid misleading calculations and possible resource overuse.
Each block or window should be defined in detail. One of the parameters that are inevitable is the state of the window. The words themselves tell us what it is about. Stateless is a type of window in a stream where records are not kept, which means that history is not collected in a certain time frame and is mainly used in windows for filtering, joins with a static table for flow enrichment or calculation at the level of one record.
Stateful is the exact opposite of that. If we define a window as stateful, we are obliged to define the time frame in which the data will be stored. It is used as a step before aggregations at the level of certain time intervals.

Mostly thanks to the development of tools from the Apache Foundation and the development of cloud solutions, today we have no shortage of streaming software. As you may have already concluded, to develop a streaming application, programming knowledge is required, while the required level of knowledge may vary depending on the complexity of the use-case and the tools you choose. In one of the following texts, we will write more precise about one of the tool from the picture below
Telco. Process and analysis of events data (CDRs). With a streaming approach, you can have real-time data or voice usage per customer and trigger additional campaigns regarding it. Using network performance data you can detect anomalies on your base stations in almost real-time. This can be used alongside your alarm system to enrich failures information.
Banking. The streaming approach will bust your time to respond in case of any fraudulent activity. Banking is probably the most promising industry when it comes to real-time use cases. One of them is customer personalization. With this approach, you can send an optimal offer depending on location, transaction, context, etc.
Retail. The retail industry also gives us a huge spectrum of use-cases to be analyzed in real-time. We can use it for better recommender systems, location-based triggers, prepare for market trends, and personalized offers. In this industry smart and on-time supply, monitoring is crucial, so inventory management can save you a lot of money and effort, for sure.
Automotive. Everyone knows about the Uber use-case. The purpose of the streaming approach is to find the nearest free car to optimize expenses and increase customer satisfaction. Traffic prediction and route optimization need to be done in a timely manner – which makes this industry a perfect ground for streaming applications.
In the competitive environment and industry, as it is today, it is really necessary to take the right steps in the shortest possible time to be ahead of the competition. Thanks to the throughput of the networks we have, the cloud, cheap hardware, and the development of the tools we use today, we can and should take all the steps to take advantage of the large amount of data that we receive in real-time from various systems, which we were not able to process until now. Suggestions would be to start with the simplest use case that fits your business and then build more advanced solutions on top of that, without rushing into complexity.
In the next post, we will write more specifically about Flink and usage in the streaming environment – stay tuned.
The cover photo is taken from https://pexels.com/@munkee-panic-272941

The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
The holiday season is the most crucial period for retailers. Besides high sales volume, it is also an opportunity to…
Read more
A closer look at analytics that matter You’ve trained your AI agent. It runs. It talks. It reacts. But does…
Read more
Imagine having a team of top chefs, but your fridge is packed with spoiled ingredients. No matter how talented they…
Read more