
After participating in a meetup at the end of March, subjected “Data Science – what is it?”, a lot of people contacted me to send them some introductory materials to help them get started with learning.
It took me a long time to sit down and start compiling a list, because there are many sources, and what I am deeply certain of is that I will end up with this sentence – it’s best to start with some realistic example that is of interest to you, because you will learn best through the exercise. Moreover, there is no golden rule how this learning path should look like, so it is very ungrateful to make a list of materials and guidelines, and to ensure that it does not enter the “bias”, or in other words- a curse of this “deterministic” movement, because that is how I approached Data Science, so it can only be done this way.
In addition, I am someone who is exclusively engaged in the application of advanced analytics within the business, where the main focus is to measure performance using some measure of success such as profit, or cost. And advanced analytics can be used in a variety of sciences and research fields, and may not be related to the business world. However, I came up with the great idea that whatever I wrote here would allow my colleagues in the field to expand this list, or to share their experience, so I invite them to make their small contribution, thus becoming the drivers of great things. ?
FAQs are an inevitable section of this text, and we will get to them, but before that I would like to look at some basics that I need to mention in order to invite reflection, and perhaps inspire inspiration for those who want to get into Data Science water.
An enormous disclaimer at the very beginning – if you expect this text to be crystal clear for you how to go tomorrow and what to learn first – be aware that this is practically impossible. In addition to the fact that the content, complexity and sphere of Data Science you will be dealing with depends primarily on your interest and background, Data Science is such a wide area that you would need to go through a whole program in basic academic studies to be able to say that you have some base basis. What I aim to do is to help you develop an approach to learning, to be aware at all times of the facts that are outlined here, and then to search for the materials and courses yourself. ? However, some of the courses checked are out of the question, so we’ll attach it to this text.
THE MAIN PRE-REQUIREMENT
As attractive as it is, Data Science is not for everyone. Like any other profession, it requires commitment. What is a basic prerequisite for success in this field is that one has to love it. So, you really need to be interested in analytics, that you like to “mine” the data round the clock to get the most out of it.
Golden Pareto also applies in Data Science. 80% is dirty work, in terms of data preparation and engineering, while this “fancy” part including the models themselves is often only about 20%. Models exist, and if you use R or Python libraries, they are generally reduced to just a few lines of code. What is more of a problem is extracting maximum information power from the data, and of course finding the optimal model configuration. In the end, the model is powerless unless the data is good – “garbage in, garbage out”.
What is often overlooked in Data Science is the importance of exploratory analysis. It happens that steps are being skipped, from the desire to start with attractive and sophisticated machine learning models as soon as possible. However, good exploratory analysis is sometimes more than half the work done. It includes dealing with data, revealing their nature, gain an understanding of the basis by which the predictive power and limitations that exist in the dataset are clear.
If you don’t like this so-called data mining, and neglect exploratory analysis, you are very unlikely to progress so quickly in career. Or simply put – this is not for you. And that’s okay, you’ll find something else that fits you better. In this text you can find even more detailed explanations and arguments regarding the beginnings in Data Science, expectations that are too high, and the reality that does not fit them.
DATA SCIENCE VS. MACHINE LEARNING VS. ARTIFICIAL INTELLIGENCE

This is something I have also talked about in a webinar, so I won’t repeat myself, but it’s important that you differentiate that these three concepts are not the same thing, and that there is a connection between them, and that as long as you think they are the same thing, you will wander. Perhaps this text will help you understand the difference a little. If not, there are many variations on the theme, choose your own. You won’t do much wrong. ?
DATA SCIENCE BUILDING BLOCKS
As most commonly argued, Data Science is a fusion of different fields – business/domain, IT and math/statistics. Depending on your background, when you start in the field of Data Science, your skills are stronger in one of these areas and weaker in the other. And that’s totally fine. What matters is that you recognize what your strengths are, because that is what differentiates you from others. When you know what your strengths are and what skills you’re missing – you know what you need to learn to move forward.
If you come from the social sciences, you have a great knowledge of the specifics of the field you are dealing with, but you lack knowledge of IT and possibly statistics. This means that if you want to deal with computer vision one day, for example, the first course you need to take must be programming-related. And this is not about mastering libraries (this comes later), but elementary programming, concepts of a given programming language, paradigms, flow control, data structures, and then getting started with math and algorithms.
If you are coming from IT, you should already have a good knowledge of programming and mathematics, but you lack a little more detailed knowledge of statistics, so a course in statistical analysis may come in handy. A domain, or business – is something that is mastered by experience. There is no perfect course that can prepare you for this, but of course you can always read a book that will bring you closer to the domain in which you would like to work. In the end, you may be an absolute beginner, and you think you lack elementary knowledge in all these areas. Start with one, when you have mastered an elemental foundation, move with another, and so until you are ready enough to be able (or forced) to juggle and learn more on the go.
“DATA SCIENTIST” PROFILES
When it comes to the different profiles of Data Scientists, depending on what they are dealing with in their daily work, requirements they are solving and skills they need to develop – there are several types of Data Scientists. It is common for everyone to love Data Science and Machine Learning, but however, their focus is different.
Analysts are more focused on exploring, identifying patterns, and explaining specific behaviors and cause and effect relationships. So they are more statisticians in nature than developers. And they have some difficulties dealing with the productionizing the solution and the model serving.
Engineers prefer to work with deep learning problems, where there are many complex mathematical formulations, and where they can try out different network architectures and play with different configurations.
Developers are mainly focused on the model delivery, how the model is going to be implemented in production, whether it will be scalable and responsive, how to keep the code clean and easily upgradeable, how some ML models will be retrained, etc.
The most important thing for storytellers is how to sell the solution to the business. What are the main benefits, how will the business profit from it, and why has it been so important to deal with a particular problem.
The profile depends a lot on the interest as well as the starting point (prior knowledge). You will not approach Data Science in the same way if you come from a business domain, and if you come from the IT world. However, the responsibilities and required skills also depend on the company itself. First of all, it depends on whether a company has the possibility to employ a number of different profiles such as Data Scientist, Data Engineer, Machine Learning Engineer, Developer and DevOps. If so – then surely Data Scientist’s job at this company will be different from that of a company that can’t afford all those profiles – and Data Scientist will be required to cover more spheres at once.
DEVELOPMENT METHODOLOGIES
One of the simplest methodologies for developing advanced analytics projects is the CRISP-DM methodology. And all the others are mostly variations on the subject, if you are well acquainted with this one, you will have an already stable foundation to do your first mini-project for the exercise. Development methodologies are important because they govern the way a problem is approached, how a solution is developed, by ensuring the maintenance of focus as well as results.
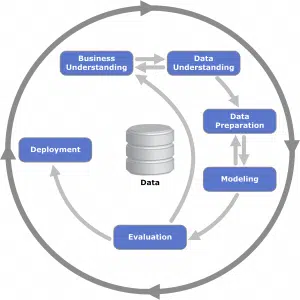
SOLUTION VS. PRODUCT
When it comes to the Data Science projects, there are generally two types of projects: solutions and products. You can find more about this here.
Solutions are projects that specialize in solving a particular problem, so they are developed for the needs of a given domain, based on a defined problem, specific in nature, and can rarely be 1/1 applied in the same way for multiple different clients, or in different business domains. The solution may be e.g. some report, a results file, or some dashboard. If the project involves the development of a time series forecasting model, e.g. sales in a retail chain that is specifically suited to modeling the behavior of that retail chain, in terms of seasonality, trends, special actions, and so on – it is a solution developed specifically for the needs of that retail chain, and cannot be applied in the field of telecommunications, e.g. . where the notion of seasonality and trend is perceived and described differently.
Products are projects that integrate advanced analytics and machine learning tools to leverage the business in the role of a decision-support system. The products are designed to be easily scalable, and can be used within different systems and different business domains, because they can solve many different problems, and thus more easily adapt to the needs of clients. The products require very detailed planning, thoroughly developed architecture and a lot of technical functionalities in order to meet different customer needs. If we make an analogy with an example of a solution, the product would imply a technical system that allows a time series forecast, regardless of whether it is within a retail chain, telecommunications, logistics, and so on.
You should already be slowly creating the outlines that each of these two types of projects entails (though not necessarily) a different set of skills, experience and knowledge. Solutions can vary in complexity, while products are extremely technically demanding, and it requires extensive experience in terms of development to develop a product that is responsive, scalable and reliable. Of course, both require knowledge of advanced analytics methods and tools.
So, in regards to the whichever is more interesting to you, or what is the main focus of development to your potential employer, there is a need to develop technical skills that will help you to be competent for the specific positions you would like to apply for.
R VS. PYTHON VS. STH ELSE
This is really (almost) irrelevant. When I started learning, I developed a recurrent network in Java. And since then, I haven’t even approached to Java (except when Spark throws an exception :D). What really matters is that you capture the concepts. You will easily google what you need. The concepts of dataframes, grouping and aggregations exist in R, Python, and Spark, and are primarily inspired by manipulations that can be done in SQL, so you can see what I’m talking about. When it comes to machine learning models, there are some variations regarding implementation in different programming languages, however, the most important thing is to understand how the algorithm works, and you can master the implementation through documentation or Stackoverflow.
R is a fantastic language, having a great community, plenty of libraries and functions, fantastic visualization capabilities. And if you don’t think you are developing serious technical systems (for which you still need a programming language for this purpose), R is a good choice.
They say that Python is the second best language for everything. If this means something to you – take this path. ? Basically, it is a general purpose language, you can run ML, you can run Deep Learning, you can create visualizations and interactive dashboards, as well as APIs, literally – whatever comes to your mind. With that, I can’t claim that everything in R exists in Python as well. Which is not to say that it won’t change anytime soon either.
There are more and more people that for the purpose of scientific programming, and more recently for advanced analytics, use Julia. However, I think Julia is still far from the level of popularity, support and community that R and Python have.
Spark is also a good option, but Spark is not always a necessary option. Basically, if you don’t need Spark’s core advantage – which is the ability to parallelize complex processes over a large scale of data – in my opinion, it should not be your first choice. Again, if you ever need to move to Spark, don’t be afraid, everything can be mastered.
There are also various ML model development tools – Orange, RapidMiner, SPSS, SAS – where everything works on the drag & drop principle, but again it’s important to understand the development methodology and models you use to make the system work. If you are not into programming, this can be a good choice.
DO I HAVE TO READ RESEARCH PAPERS/OWN A PHD?
PhD is the biggest misconception I have come across over the years reading various texts and FAQs on how to get started with Data Science. There is one thing you need to understand – PhD is important if you are involved in scientific research, where your main focus is to develop new machine learning algorithms, Thus, not as a title, but in terms of the knowledge and experience necessary to develop new algorithms. This implies that you have an extensive knowledge of linear algebra, numerical analysis, combinatorics, and many other things (which really requires years of commitment).
On the other hand, a PhD from a specific domain can be a useful reference, since in that case you know the specifics of the domain where you could apply advanced analytics. However, it can also be problematic with poor practical experience. Will the title help you enroll faster, or get a job in Data Science at all? Not necessarily. The truth is somewhere in the middle.
As for reading scientific papers – this is a must. Data Science involves the daily browsing, reading and comparison of scientific papers, because it is academia that (along with industry) is pushing the boundaries. When working on a Data Science problem, the most important thing is to be aware of limits, which is all that can be done. The boundaries are defined by how far the academy has arrived with research work, and by what is applicable in the industry. When you are aware of these options – you will be able to solve any problem you encounter.
WHY ARE THE INFLUENCERS SO IMPORTANT?
In addition to books, research papers, courses, and blog posts, there’s another “instant” way to get relevant information and insights, that is – through the social networks. LinkedIn, Reddit and Twitter are my favorites so far, though of course there are others. This way you can follow the leaders in this field, always stay up-to-date, connect with people of similar interests and share experiences and knowledge, and in turn, gain the knowledge. I have already talked about this in my text, and what I can say after a year is yes – I still believe it. ?
OK, LET’S TALK SOME BUSINESS
- Statistical learning by T. Hastie and R. Thibsirani (this course is realted to “An introduction to statistical learning”, attached below): https://online.stanford.edu/courses/sohs-ystatslearning-statistical-learning
- ML by Andrew Ng: https://www.coursera.org/learn/machine-learning#about
- Deep Learning Specialization by Andrew Ng: https://www.coursera.org/specializations/deep-learning
- One of the best courses for recommender systems: https://www.coursera.org/specializations/recommender-systems?#courses (with this course you should also keep this book, linked below as a recipe, where you can read some of the details, we do not recommend reading the book from first to the last page… You are just pick up what you need: Recommender Systems Handbook)
- Case studies – beside classic courses for introduction with Python i ML libraries, it shows some real world Data
- Science problems
PluralSight (free of charge April, one must not miss this chance)
- Python fundamentals: https://www.pluralsight.com/browse/software-development/python
Podcasts
Books
-
- Books
- Introducing Python
- Hands-On Machine Learning with Scikit-Learn and TensorFlow
- Learning Spark
- Learning PySpark
- Mining massive datasets (there also exists a Stanford course relying on this book, which nails it: https://online.stanford.edu/courses/soe-ycs0007-mining-massive-data-sets)
- Introduction to statistical learning (explains all the basic concepts of statistical learning, through algorithms and examples)
- The Elements of Statistical Learning (covers similar areas as the previous one, with complex math, the previous one was written based on this one and is closer to beginners)
- Excellent book for beginners in R: https://www.amazon.com/Data-Science-Transform-Visualize-Model/dp/1491910399
Blogs
Deep learning
- Martin Gorner’s presentation, “TensorFlow and Deep Learning without a PHD (Part 1 and 2)”
- Pretty detailed and comprehensive blog about deep learning: Colah’s blog
- Deep learning specialization – best deep learning materials ever. The first course – what is the structure of the neural network and how it works, the second course – parameters and tuning, the third – conceptual (how to check that the network is wrong and what to do), the fourth – convolution (computer vision), the fifth – RNN (nlp, audio)
- Book: http://www.deeplearningbook.org/lecture_slides.html
Communities
NEXT STEPS
Get involved in community – attend all possible meetups, conferences and lectures, you can always get good advices, ideas, new knowledge, etc. at such events.
Get comfortable with the theoretical basics of advanced analytics (development methodologies, data exploration, statistical tests, machine learning algorithms, …)
Find an example that is interesting to you, through which you could apply that you are learning and expand your knowledge (UCI machine learning repository and Google dataset search repository have millions of open datasets, you will surely find something of interest)
Learn how to GOOGLE
The project you’re working should be uploaded on your GitHub profile, it’s a must-have and essential bullet in your CV
Make a report in which you will explain what you did in the project, what problem was solved, what were the steps, what were the biggest challenges, what conclusions were drawn and on what basis, what are the possibilities for improvements, etc…
Ask someone from the community who is involved in areas you are interested in for advice on how to get started in that particular area (data science is a broad term)
Apply for a practice / job, where you will best learn and develop through the mentorship. If there is a technical test in the selection phase – that is the perfect opportunity to learn something. Use it!
ACKNOWLEDGEMENTS
I would like to thank everyone who helped in the realization of this document, especially to my colleagues from the TS team (thank you Angela, Jasmina, Tijana, Marija, Strahinja, Marko, Bogdane!). And special thanks go to my colleagues Bojana Soro from Content Insights and Srdjan Santic from Logikka. Together, we have compiled a list of starting materials and formulated this document. THANK YOU ALL! I hope this document will be helpful to beginners, and that we will improve and enrich it through the community. Cheers! ?